

Τι είναι ένα Data Warehouse

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Στο άρθρο αυτό θα αναλύσουμε τι είναι το Data Warehouse, από τι αποτελείτε και ποια είναι η χρησιμότητα του.
Στην εποχή της πληροφορικής η διαχείριση των δεδομένων που ολοένα αυξάνονται γίνεται συνεχώς πιο δύσκολη. Θέλουμε να αξιοποιήσουμε τα δεδομένα αυτά και ταυτόχρονα να μην καθυστερεί η εφαρμογή μας.
Το Data Warehouse είναι ένα σύστημα που χρησιμοποιείτε για ανάλυση δεδομένων. Εκεί συλλέγονται δεδομένα (ETL) σε μια βάση δεδομένων που ονομάζεται staging από διάφορες πηγές όπως transactional βάσεις (OLTP) και Big Data και αφού πραγματοποιηθεί κάποια εκκαθάριση στα δεδομένα (cleansing / data quality ) αυτά μεταφέρονται στη βάση του Data Warehouse (OLAP) ως μικρές οντότητες (Data Marts). Από εκεί και πέρα γίνεται σύνδεση του Data Warehouse με τα Reporting Tools όπως Power BI, Excel, QLik , Tableau κ.τ.λ. ώστε να φτάσει η πληροφορία στον τελικό χρήστη.
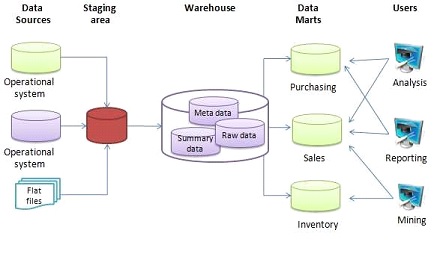
Με τι τρόπο είναι κατανεμημένα τα δεδομένα σε ένα Data Warehouse;
Η πιο δημοφιλής τεχνική ανάλυσης δεδομένων είναι η χρήση Πολυδιάστατων κύβων που ονομάζονται και OLAP Cubes (Online analytical processing) .
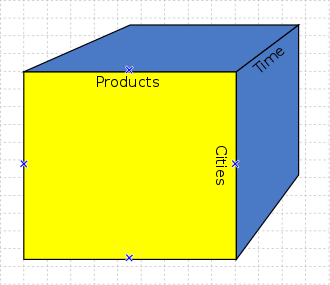
Εκεί τα δεδομένα μας χωρίζονται σε διαστάσεις(dimensions) που μπορεί να είναι ο χρόνος, το προϊόν, γεωγραφική περιοχή, … και σε fact που το κάθε κελί περιέχει μια μέτρηση(measure) που μπορεί να είναι ο αριθμός πωλήσεων που έχουν γίνει, το κέρδος, το κόστος κ.τ.λ.. Επίσης τα aggregations (π.χ. μέσος όρος / σύνολο / κατώτατων πωλήσεων) προ-υπολογίζονται και αποθηκεύονται κατά την ενημέρωση του κύβου με τα καινούργια δεδομένα μέσω μια διαδικασίας που ονομάζεται process.
Πως αποθηκεύονται τα δεδομένα σε έναν πολυδιάστατο κύβο;
Τα δεδομένα ενός πολυδιάστατου κύβου αποθηκεύονται με τη μορφή είτε Star Schema είτε Snowflake Schema πριν δούμε όμως αναλυτικά τι σημαίνουν αυτές οι δύο μορφές θα πρέπει γνωρίζουμε τους τρεις παρακάτω όρους.
Fact tables (πίνακας γεγονότων)
Στον Fact table καταγράφονται οι μετρήσεις(measures) συγκεκριμένων γεγονότων όπως αριθμός πωλήσεων που έγιναν, κόστος και κέρδος. Επίσης περιέχονται τα foreign keys τα οποία επιτρέπουν τη σύνδεση τους με τα dimension tables.
Για να διασφαλιστεί η μοναδικότητα της κάθε εγγραφής μέσα στον χρόνο καθώς μπορεί να έχουν γίνει μεταβολές στη πηγή που προήλθαν τα δεδομένα, ως primary key ορίζεται ένας μοναδικός αριθμός που ονομάζεται Surrogate key.
Dimension tables (πίνακες διαστάσεων)
Στα Dimension tables έχουμε τα δεδομένα των διαστάσεων που μπορεί να είναι κοινά για τις μετρήσεις(measures) που έχουμε στα Fact tables όπως ο χρόνος, ο υπάλληλος, το προϊόν και το κατάστημα.
Η χρήση του Surrogate key για να διασφαλιστεί η μοναδικότητα τον εγγράφων υπάρχει και σε αυτά.
Data Marts
Κάθε ξεχωριστή οντότητα ενός θέματος όπως για παράδειγμα οικονομικά ή πωλήσεις ονομάζεται Data Mart και περιέχει το δικό της Facts Table μαζί με τα Dimension Tables
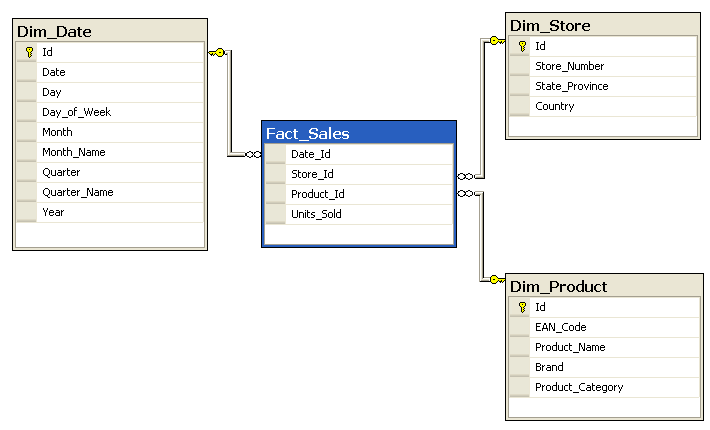
Star Schema
Σε ένα πολυδιάστατο Data Warehouse η πιο απλή μορφή ενός Data Mart είναι ένα Star Schema. Το κάθε Dimension Table συνδέεται απευθείας με το Fact Table μέσω του Foreign Key.
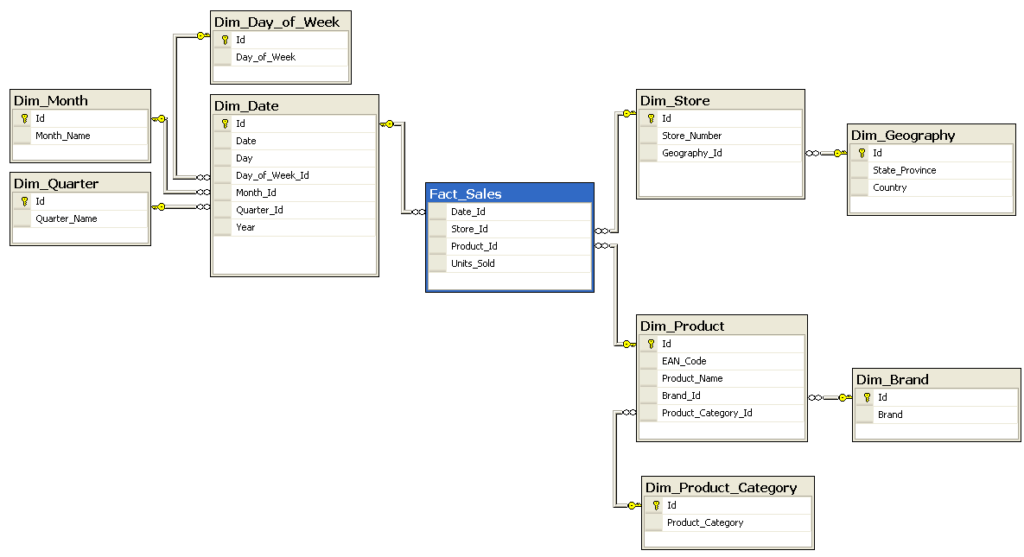
Snowflake Schema
To Snowflake Schema είναι μια πιο προχωρημένη έκδοση του Star Schema. Η διαφορά του είναι ότι οι Dimension tables κανονικοποιούνται σε μικρότερους υπό-πίνακες. Η χρήση τους συνιστάτε σε περιπτώσεις που η ταχύτητα ανάκτησης δεδομένων είναι πιο σημαντική από την ανάκτηση της αναλυτικής πληροφορίας.
Πλεονεκτήματα χρήσης Data Warehouse:
- Συνδυάζει δεδομένα από πολλές διαφορετικές πηγές. Σαν αποτέλεσμα είναι εύκολο να εξάγουμε μετά τα δεδομένα με ένα query.
- Δεν δημιουργεί blocks στις παραγωγικές βάσεις OLTP. Καθώς τα δεδομένα έχουν αντιγραφεί στη υποδομή του Data Warehouse.
- Παρέχει ιστορικότητα των δεδομένων μέσα στο χρόνο ακόμα και αν έχουν γίνει αλλαγές στη OLTP βάση χάρη στη χρήση του Surrogate key.
- Προσφέρει ξεκαθάρισμα στα δεδομένα. Αφαιρώντας όση πληροφορία μπορεί να οδηγήσει σε λάθος συμπεράσματα. Επίσης μπορεί να διορθώσει λάθος πληροφορίες π.χ. τυπογραφικά.
- Προσφέρει υψηλή απόδοση ακόμη και σε πολύπλοκα queries ανάλυσης δεδομένων.