

What is a Data Warehouse?

Certifications:

In this article we will analyze what it is Data Warehouse, what you are made of and what is its utility.
In the age of IT, managing the ever-increasing data is becoming more and more difficult. We want to make use of this data and at the same time not to delay our application.
The Data Warehouse is a system you use for data analysis. There data is collected (ETL) in a database called staging from various sources such as transactional databases (OLTP) and Big Data and after some cleansing has been performed on the data (cleansing / data quality ) these are transferred to its base Data Warehouse (OLAP) as small entities (Data Marts). From there, the Data Warehouse is connected to the Reporting Tools such as Power BI, Excel, QLik, Tableau, etc. so that the information reaches the end user.
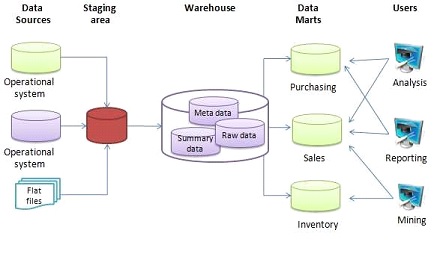
How is data distributed in a Data Warehouse?
The most popular data analysis technique is using Multidimensional cubes which are called and OLAP Cubes (Online analytical processing) .
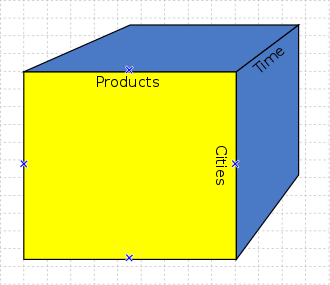
There our data is divided into dimensions (dimensions) which can be time, product, geographical area, … and in fact where each cell contains a count (measure) which can be the number of sales made, the profit, the cost, etc.. Also the aggregations (eg average / total / bottom sales) are pre-calculated and stored when updating the cube with the new data through a process called process.
How is data stored in a multidimensional cube?
The data of a multidimensional cube is stored in the form of either Star Schema either Snowflake Schema but before we see in detail what these two forms mean we should know the three terms below.
Fact tables
To Fact table measurements are recorded (measures) of specific facts such as number of sales made, cost and profit. Also included are foreign keys which allow their connection with the dimension tables.
To ensure the uniqueness of each record over time as changes may have been made to the source of the data, a unique number called a primary key is defined as Surrogate key.
Dimension tables
Sta Dimension tables we have the dimensional data that may be common for measurements (measures) which we have in Fact tables such as time, employee, product and store.
Its use Surrogate key to ensure the uniqueness of the documents it exists in them as well.
Data Marts
Each separate entity of a subject such as for example finance or sales is called Data Mart and contains its own Facts Table along with Dimension Tables
Star Schema
In a multidimensional Data Warehouse the simplest form of a Data Mart it is one Star Schema. Each Dimension Table is directly linked to the Fact Table through the Foreign Key.
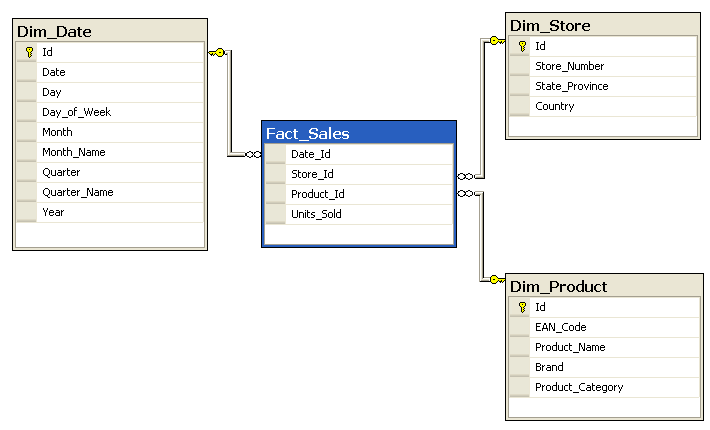
Snowflake Schema
That Snowflake Schema is a more advanced version of it Star Schema. Its difference is that Dimension tables are normalized into smaller sub-tables. Their use is recommended in cases where the speed of data recovery is more important than the recovery of detailed information.
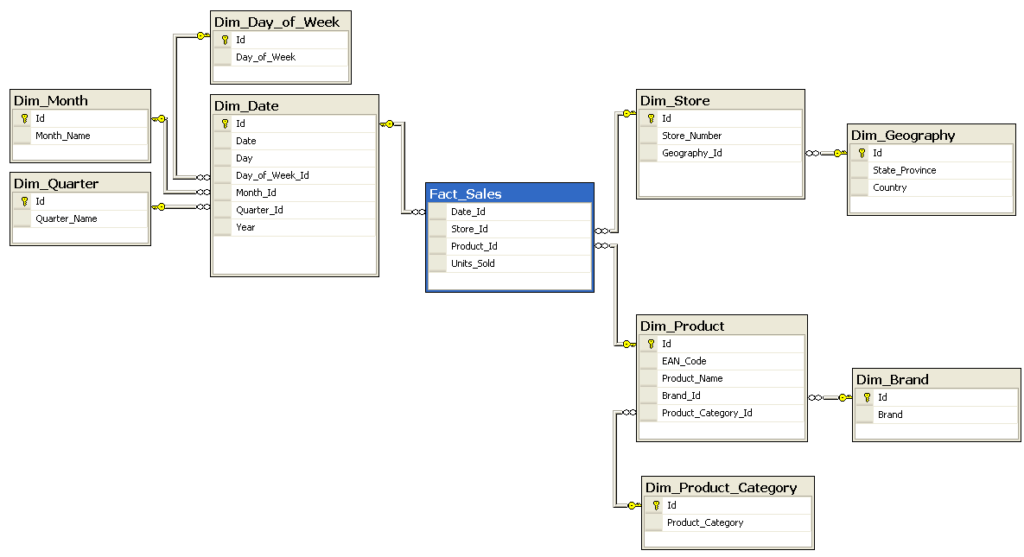
Advantages of using Data Warehouse:
- It combines data from many different sources. As a result it is easy to extract the data with a query.
- It does not create blocks in the production OLTP bases. As the data has been copied to the Data Warehouse infrastructure.
- It provides historical data over time even if changes have been made to the OLTP database thanks to the use of the Surrogate key.
- It offers clarity to the data. Removing as much information can lead to wrong conclusions. It can also correct wrong information, e.g. typographical.
- It offers high performance even in complex data analysis queries.