Pivoting in Microsoft Excel using Python

Certifications:

In an earlier article we have seen the possibilities to perform Excel functions such as vlookup through Python. In this article we will see how we can perform pivoting through Python.
We will analyze ways so that we can find information such as, which customer made the most expensive purchases or the total amount spent on each product, etc.
Let's see the steps one by one, starting with the resources.
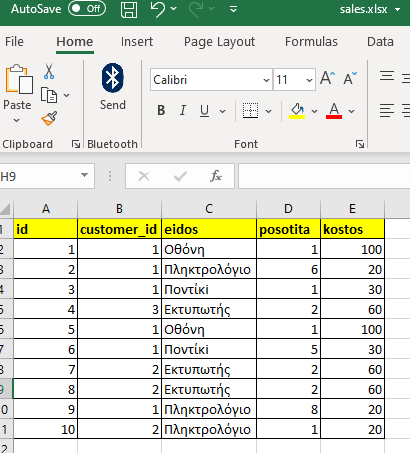
We have an Excel file with the total sales named sales.xlsx.
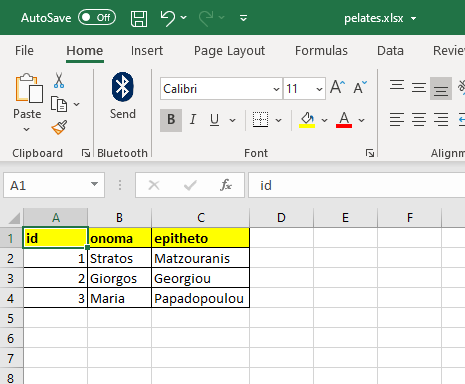
There is a second Excel file with the customer names called pelates.xlsx.
Apart from having Python installed, we will need the following libraries which are easily installed by running the following commands in the command prompt.
pip install xlrd pip install pandas pip install numpy pip install openpyxl
We import the libraries.
import pandas as pd import numpy as np
We fill 2 dataframe variables with the records of each Excel. With the sheet_name parameter we can also choose the gender where the data is located.
df_pelates = pd.read_excel('pelates.xlsx',sheet_name='Sheet1')
df_sales = pd.read_excel('sales.xlsx',sheet_name='Sheet1')
We should rename the id field to customer_id so that it has the same name as it has in the sales dataframe.
df_pelates.rename(columns={'id':'customer_id'}, inplace=True)
In this step the vlookup, we merge both dataframes into a new one (df_final) in the customer_id field. In the how parameter we declare the way it will be done join as in SQL we have options left, right, outer, inner.
By choice right we declare that we want all the records from the second dataframe, linking to those linked to the first
If there is no common customer_id it will have the value NaN/Null or else the blank.
df_final = pd.merge(df_pelates, df_sales, on='customer_id', how='right')
Let's see the fields that the merged dataframe now has.
print(df_final.columns)
We can also choose which fields of these to keep.
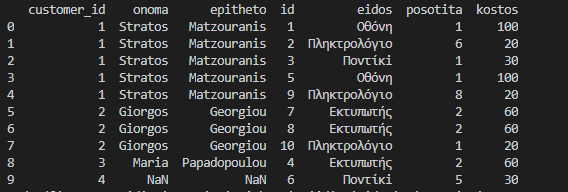
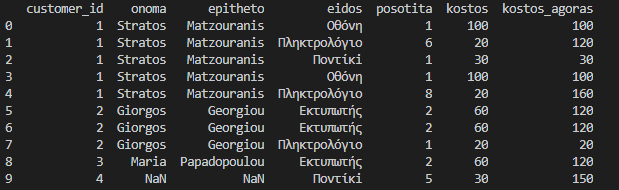
df_final = df_final[['onoma','epitheto','eidos','posotita','kostos']]
The result so far is this.
print(df_final)
Now calculate the actual cost spent with each purchase by multiplying the quantity by the cost.
df_final['kostos_agoras'] = df_final['posotita']*df_final['kostos']
At this moment, however, we do not know how much money each customer has consumed. We can easily with one line of code group by customer and have the total cost for each.
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).sum()
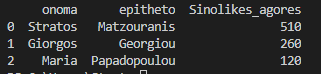
Let's rename the sum field to "Total Purchases"
df_final.rename(columns={'kostos_agoras':'Sinolikes_agores'}, inplace=True)
Let's see what we did.
df_final = df_final[['onoma','epitheto','Sinolikes_agores']] print(df_final)
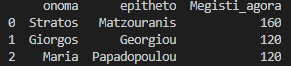
We can instead of sum use another function like max to find the maximum purchase made by the customer.
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).max()
df_final.rename(columns={'kostos_agoras':'Megisti_agora'}, inplace=True)
df_final = df_final[['onoma','epitheto','Megisti_agora']]
print(df_final)
We can count how many purchases each customer has made (count).
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).count()
df_final.rename(columns={'kostos_agoras':'plithos_agorwn'}, inplace=True)
df_final = df_final[['onoma','epitheto','plithos_agorwn']]

We can group by product.
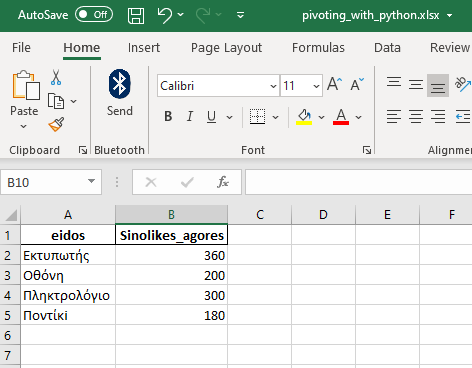
df_final = df_final.groupby(['eidos'],as_index=False).sum() df_final = df_final[['eidos','kostos_agoras']] print(df_final)
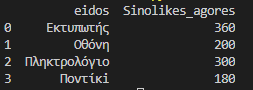
Final result
Finally we can save the results in a new Excel file.
df_final.to_excel('pivoting_with_python.xlsx', index=False)