Pivoting στο Microsoft Excel με τη χρήση Python

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Σε παλαιότερο άρθρο έχουμε δει τις δυνατότητες να πραγματοποιήσουμε functions του Excel όπως η vlookup μέσω Python. Σε αυτό το άρθρο θα δούμε πως μπορούμε να πραγματοποιήσουμε pivoting μέσω Python.
Θα αναλύσουμε τρόπους ώστε να μπορούμε να βρούμε πληροφορία όπως, ποιος πελάτης έκανε τις ακριβότερες αγορές ή το συνολικό ποσό που δαπανήθηκε για το κάθε προϊόν, κ.τ.λ..
Πάμε να δούμε ένα ένα τα βήματα ξεκινώντας από τα resources.
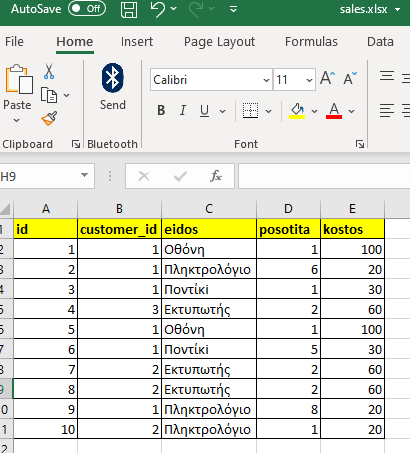
Έχουμε ένα αρχείο Excel με το σύνολο πωλήσεων με όνομα sales.xlsx.
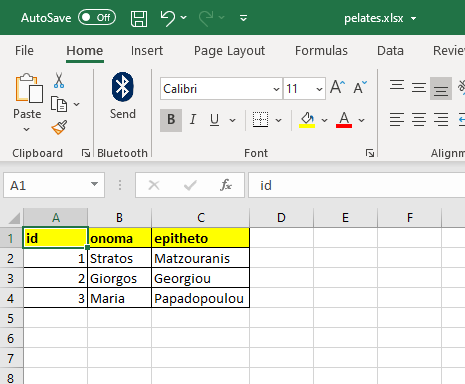
Υπάρχει ένα δεύτερο αρχείο Excel με τα ονόματα των πελατών που ονομάζεται pelates.xlsx.
Πέρα από το να έχουμε εγκαταστήσει την Python, θα χρειαστούμε τις κάτωθι βιβλιοθήκες που γίνονται εύκολα εγκατάσταση με μια εκτέλεση των κάτωθι εντολών στο command prompt.
pip install xlrd pip install pandas pip install numpy pip install openpyxl
Κάνουμε import τις βιβλιοθήκες.
import pandas as pd import numpy as np
Γεμίζουμε 2 μεταβλητές dataframe με τις εγγραφές του κάθε Excel. Με την παράμετρο sheet_name μπορούμε να διαλέξουμε και το φύλο που βρίσκονται τα δεδομένα.
df_pelates = pd.read_excel('pelates.xlsx',sheet_name='Sheet1')
df_sales = pd.read_excel('sales.xlsx',sheet_name='Sheet1')
Θα πρέπει να κάνουμε μετονομασία το πεδίο id σε customer_id, ώστε να έχει το ίδιο όνομα που έχει και στο dataframe των sales.
df_pelates.rename(columns={'id':'customer_id'}, inplace=True)
Σε αυτό το βήμα γίνεται ουσιαστικά το vlookup, ενώνουμε και τα 2 dataframes σε ένα καινούργιο (df_final) στο πεδίο customer_id. Στη παράμετρο how δηλώνουμε τον τρόπο που θα γίνει join όπως ισχύει και στην SQL έχουμε επιλογές left,right,outer,inner.
Με την επιλογή right δηλώνουμε ότι θέλουμε όλες τις εγγραφές από το δεύτερο dataframe, συνδέοντας με όσα συνδέονται με το πρώτο
Αν δεν υπάρχει κοινό customer_id θα έχει την τιμή NaN/Null ή αλλιώς το κενό.
df_final = pd.merge(df_pelates, df_sales, on='customer_id', how='right')
Για να δούμε τα πεδία που έχει τώρα το ενωμένο dataframe.
print(df_final.columns)
Μπορούμε επίσης να διαλέξουμε ποια πεδία από αυτά θα κρατήσουμε.
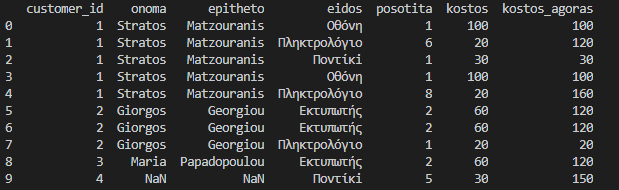
df_final = df_final[['onoma','epitheto','eidos','posotita','kostos']]
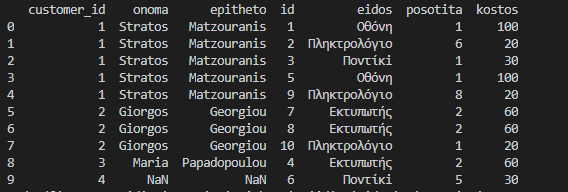
Το αποτέλεσμα μέχρι στιγμής είναι αυτό.
print(df_final)
Τώρα να υπολογίσουμε το πραγματικό κόστος που δαπανήθηκε με την κάθε αγορά πολλαπλασιάζοντας την ποσότητα με το κόστος.
df_final['kostos_agoras'] = df_final['posotita']*df_final['kostos']
Αυτή την στιγμή όμως δεν ξέρουμε πόσα χρήματα έχει καταναλώσει ο κάθε πελάτης. Μπορούμε εύκολα με μία γραμμή κώδικα να κάνουμε group by ανά πελάτη και να έχουμε το σύνολο του κόστους για το καθέναν.
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).sum()
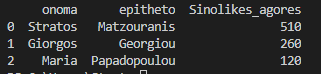
Ας κάνουμε rename το πεδίο του sum σε «Συνολικές αγορές»
df_final.rename(columns={'kostos_agoras':'Sinolikes_agores'}, inplace=True)
Να δούμε τι κάναμε.
df_final = df_final[['onoma','epitheto','Sinolikes_agores']] print(df_final)
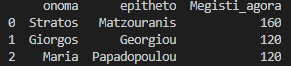
Μπορούμε αντί για sum να χρησιμοποιήσουμε άλλη function όπως η max για να βρούμε τη μέγιστη αγορά που έκανε ο πελάτης.
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).max()
df_final.rename(columns={'kostos_agoras':'Megisti_agora'}, inplace=True)
df_final = df_final[['onoma','epitheto','Megisti_agora']]
print(df_final)
Μπορούμε να μετρήσουμε πόσες αγορές έχει κάνει ο κάθε πελάτης(count).
df_final = df_final.groupby(['customer_id','epitheto','onoma'],as_index=False).count()
df_final.rename(columns={'kostos_agoras':'plithos_agorwn'}, inplace=True)
df_final = df_final[['onoma','epitheto','plithos_agorwn']]

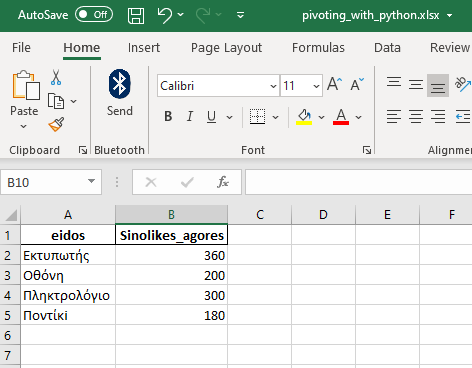
Μπορούμε να κάνουμε group by ανά προϊόν.
df_final = df_final.groupby(['eidos'],as_index=False).sum() df_final = df_final[['eidos','kostos_agoras']] print(df_final)
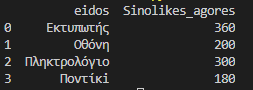
Τελικό αποτέλεσμα
Τέλος μπορούμε να αποθηκεύσουμε τα αποτελέσματα σε ένα καινούργιο αρχείο Excel.
df_final.to_excel('pivoting_with_python.xlsx', index=False)