

Πώς μπορούμε μέσα από τον SQL Server να διαβάζουμε Excel / CSV / TXT και να εισάγουμε τις εγγραφές σε πίνακα

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Ο SQL Server μας δίνει την δυνατότητα να διαβάσουμε και να εισάγουμε αρχεία κατά βούληση χωρίς την χρήση πακέτων SSIS (Integration Services) και Wizard. Η διαδικασία αυτή γίνεται με τη χρήση του function OPENROWSET και του BULK INSERT. Μπορούμε να καλέσουμε με απευθείας T-SQL query είτε να εισάγουμε το statement σε κάποιο agent job.
Χάρη σε αυτές τις λειτουργίες μπορούμε ακόμη να εισάγουμε τις εγγραφές απευθείας σε κάποιον υπάρχον πίνακα.
Τα προ-απαιτούμενα για την χρήση του ACE OLEDB engine
Θα πρέπει να εγκαταστήσουμε ACE Engine (υπάρχει εδώ για κατέβασμα). Αν υπάρχει εγκατεστημένος ήδη κάποιος συμβατός provider π.χ. Microsoft.ACE.OLEDB.12.0 τότε δεν χρειάζεται να εγκαταστήσουμε κάποιο άλλο.
Για να δούμε τους εγκατεστημένους providers τρέχουμε το κάτωθι:
exec master.dbo.sp_MSset_oledb_prop
Επίσης πρέπει να ρυθμίσουμε την χρήση των providers στο SQL Server instance εκτελώντας το παρακάτω script:
/* sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'Ad Hoc Distributed Queries', 1; GO RECONFIGURE; GO EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.12.0′, N'AllowInProcess', 1 GO EXEC master.dbo.sp_MSset_oledb_prop N'Microsoft.ACE.OLEDB.12.0′, N'DynamicParameters', 1 GO --Προσοχή το script ανάλογος ποιο ACE engine διαλέξουμε βάζουμε το αντίστοιχο π.χ. Microsoft.ACE.OLEDB.12.0, Microsoft.ACE.OLEDB.16.0 κλπ. */
Πώς διαβάζουμε μέσα από αρχείο Excel
Το μόνο που χρειάζεται να κάνουμε είναι να τρέξουμε το παρακάτω query αφού πρώτα βάλουμε την αντίστοιχη έκδοση με αυτή που έχουμε εγκαταστήσει π.χ. ‘Microsoft.ACE.OLEDB.12.0’, επιλέξουμε ως Database το direct path για το αρχείο που θέλουμε π.χ. ‘C:\Users\smatzouranis\Desktop\test.xlsx’ και τέλος ορίσουμε το όνομα του Sheet που θα διαβάσουμε:
SELECT * FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0', 'Excel 12.0;Database=C:\Users\smatzouranis\Desktop\test.xlsx','select * from [Sheet1$]')
Όταν το εκτελέσουμε θα μας εμφανίζει στο αποτέλεσμα απευθείας στο grid:
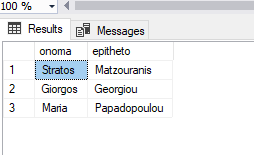
Πώς εισάγουμε σε έναν πίνακα τις εγγραφές από αρχείο Excel
Μπορούμε όμως το αποτέλεσμα όχι απλά να το δούμε αλλά και να το αποθηκεύσουμε, οπότε ας φτιάξουμε έναν πίνακα που να ταιριάζει στα δεδομένα που έχουμε:
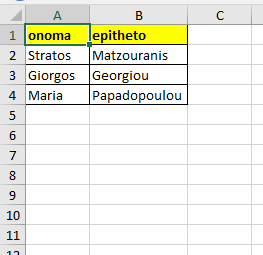
Φτιάχνουμε έναν πίνακα με δύο πεδία για κείμενο:
CREATE table test( onoma varchar(50), epitheto varchar(50))
Στο παράδειγμα αυτό θα το κάνουμε λίγο πιο πολύπλοκο καθώς θα διαβάζουμε από έναν φάκελο που θα έχει την σημερινή ημερομηνία, οπότε το path του φακέλου που θα ορίζεται σε μία παράμετρο με το OPENROWSET θα αλλάζει δυναμικά ανά ημέρα.
Για να το πετύχουμε αυτό θα κάνουμε χρήση τη function getdate() στο query του OPENROWSET, το οποίο θα το περάσουμε σε μία παράμετρο, στη συνέχεια θα κάνουμε insert into στον πίνακα που φτιάξαμε πριν εκτελόντας αυτή τη παράμετρο:
set ANSI_NULLS ON
GO
set QUOTED_IDENTIFIER ON
GO
declare @dbfile varchar(2000);
print @dbfile
set @dbfile = 'SELECT * FROM OPENROWSET(''Microsoft.ACE.OLEDB.12.0'''+','+'''Excel 12.0;Database=C:\Users\smatzouranis\outlook_files\'+convert(varchar,getdate(),112)+'\test_'+convert(varchar,getdate(),112)+'.xlsx'''+','+'''select * from [Sheet1$]'''+')'
print @dbfile
insert into dbo.test
exec(@dbfile)
go
(3 rows affected)
Έτσι πλέον στον πίνακα test υπάρχουν οι εγγραφές:
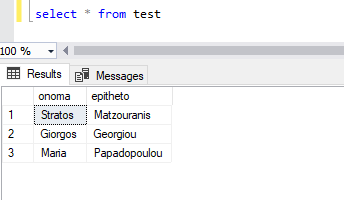
Πάμε να δούνε τι κάνουμε σε περίπτωση που δεν έχουμε Excel αρχείο αλλά flatfile CSV / TXT.
Πώς διαβάζουμε μέσα από αρχείο CSV / TXT
Η διαδικασία είναι παρόμοια με την διαφορά ότι δηλώνουμε το όνομα του αρχείου στο path αλλά στο τέλος αντί το όνομα του Sheet. Ως delimiter χαρακτήρας για τον διαχωρισμό της κάθε στήλης πρέπει να είναι το comma ‘,’ . Υπάρχει η παράμετρος HDR η οποία δηλώνει ότι στην πρώτη γραμμή έχουμε τον τίτλο του πεδίου οπότε να αγνοήσει ή οχι την πρώτη γραμμή, στην περίπτωση μας έχει τίτλο οπότε βάζουμε HDR=YES:
SELECT * FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0', 'Text;Database=C:\Users\smatzouranis\Desktop\;HDR=YES','select * from [test.csv]')
Πώς εισάγουμε σε έναν πίνακα τις εγγραφές από αρχείο CSV / TXT
Αντίστοιχα μπορούμε να εισάγουμε τις εγγραφές σε πίνακα όπως είδαμε και στο προηγούμενο παράδειγμα:
set ANSI_NULLS ON
GO
set QUOTED_IDENTIFIER ON
GO
declare @dbfile varchar(2000);
print @dbfile
set @dbfile = 'SELECT * FROM OPENROWSET(''Microsoft.ACE.OLEDB.12.0'''+','+'''Text;Database=C:\Users\smatzouranis\outlook_files\'+convert(varchar,getdate(),112)+'\;HDR=YES'''+','+'''select * from [test.csv]'''+')'
print @dbfile
insert into dbo.test
exec(@dbfile)
go
(3 rows affected)
Τι κάνουμε στην περίπτωση που το CSV / TXT αρχείο δεν είναι comma delimited αλλά έχει custom delimiter ή encoding
Σε αυτή τη περίπτωση δεν αλλάζουμε κάτι στο query μας αλλά στον φάκελο που περιέχει τα αρχεία θα πρέπει να δημιουργήσουμε ένα αρχείο με όνομα schema.ini, σε αυτό το αρχείο ορίζουμε το ακριβές όνομα του αρχείου, αν στην πρώτη γραμμή έχει τον τίτλο του κάθε πεδίου και τον custom delimiter που έχει όπως στο παρακάτω παράδειγμα με pipe delimiter:
[test.csv]
ColNameHeader=False
Format=Delimited(|)
MaxScanRows=0
CharacterSet=65001
Col1="Col1" text
Col2="Col2" textΠώς εισάγουμε τις εγγραφές από CSV / TXT με BULK INSERT
Σε περίπτωση που το αρχείο που θέλουμε να εισάγουμε ένα αρχείο που περιέχει πάνω από 255 κολώνες ή στην περίπτωση που δεν θέλουμε να κάνουμε χρήση του configuration αρχείου schema.ini τότε ο μόνος τρόπος να το εισάγουμε είναι με BULK INSERT.
Ένα σύνηθες σφάλμα σε αρχεία με πάνω από 255 κολώνες είναι το παρακάτω:
This operation will fail because the text file you are about to import contain more than 255 columnsΣε αυτή τη περίπτωση σε αντίθεση με την χρήση του Microsoft.ACE.OLEDB αποφεύγουμε τον περιορισμό αυτό, δεν χρειάζόμαστε ένα configuration αρχείο αλλά μέσα στο SQL statement δηλώνουμε τον delimiter και το codepage:
BULK INSERT dbo.test FROM 'C:\Users\smatzouranis\Desktop\test.csv' WITH (FIRSTROW=1,FIELDTERMINATOR = '|',ROWTERMINATOR = '\n', CODEPAGE = 65001);
Πώς μπορούμε κατά την εισαγωγή του πίνακα να κρατάμε και την τρέχουσα ημερομηνία
Ας δούμε ένα ακόμα παράδειγμα, μπορούμε όταν εισάγουμε τις εγγραφές να έχουμε και την σημερινή ημερομηνία και ώρα.
Σβήνουμε τον πίνακα και τον ξαναφτιάχνουμε με ένα ακόμα πεδίο datetime:
drop table test; CREATE table test( onoma varchar(50), epitheto varchar(50), imerominia datetime)
Η μόνη διαφορά είναι ότι έχουμε προσθέσει στο select μετά το * την function getdate():
set ANSI_NULLS ON
GO
set QUOTED_IDENTIFIER ON
GO
declare @dbfile varchar(2000);
print @dbfile
set @dbfile = 'SELECT *,getdate() FROM OPENROWSET(''Microsoft.ACE.OLEDB.12.0'''+','+'''Text;Database=C:\Users\smatzouranis\outlook_files\'+convert(varchar,getdate(),112)+'\;HDR=YES'''+','+'''select * from [test.csv]'''+')'
print @dbfile
insert into dbo.test
exec(@dbfile)
go
Bonus αυτόματη δημιουργία των εντολών για OPENROWSET / BULK INSERT
Αν φτιάξουμε και γεμίσουμε ένα βοηθητικό πίνακα που θα περιέχει την σύνδεση μεταξύ των πινάκων που θέλουμε να γεμίσουμε και των αρχείων, μπορούμε να κάνουμε generate όλα τις εντολές που θα χρειαστούμε όπως:
- Το select των αρχείων
- Το insert στους πίνακες με openrowset
- Το insert στους πίνακες με bulk insert
- Την δημιουργία του schema.ini
- Το truncate των πινάκων
- Την διαγραφή των πινάκων
- Αλλά ακόμα και να ενημερώσουμε μια στήλη στον βοηθητικό μας αυτό πίνακες με το count των εγγραφών μετά την εισαγωγή
Για να γίνει αυτό φτιάχνουμε τον βοηθητικό πίνακα όπως παρακάτω και εισάγουμε τους πίνακες με τα αρχεία που θα φορτώσουμε:
CREATE TABLE [dbo].[filenames](
[name] [varchar](100) NULL,
[table_name] [varchar](100) NULL,
[count] [numeric](20, 0) NULL,
CONSTRAINT [ak_name] UNIQUE NONCLUSTERED
(
[name] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
--insert into filenames values ('customers_file','customers_table',null);
--insert into filenames values ('countries_file','countries_table',null);
Και έπειτα τρέχοντας το παρακάτω query θα γίνουν generate οι εντολές:
select
(name+'.csv') as real_fname
,('SELECT * FROM OPENROWSET(''Microsoft.ACE.OLEDB.12.0'',''Text;Database=C:\demo\;'',''select * from [' +name+'.csv]'');') as select_st
,('insert into dbo.' +fn.table_name +' SELECT * FROM OPENROWSET(''Microsoft.ACE.OLEDB.12.0'',''Text;Database=C:\demo\;'',''select * from [' +name+'.csv]'');') as insert_st
,('BULK INSERT dbo.' +fn.table_name +' FROM ''C:\demo\' +name+'.csv'' WITH (FIELDTERMINATOR = ''|'',ROWTERMINATOR = ''\n'', CODEPAGE = 65001);') as bulk_insert_st
,('update dbo.filenames set count=(select count(*) from '+fn.table_name+ ') where table_name='''+fn.table_name+''';') as count_st
,(REPLACE('['+name+'.csv]'+char(13)+char(10)+'ColNameHeader=false Format=Delimited(|) MaxScanRows=0 TextDelimiter=none CharacterSet=65001 '+CL.COL_TYPE+char(13)+char(10)+char(13),' ',char(13)+char(10))) as schema_ini
,('truncate table dbo.'+fn.table_name+';') as truncate_st
,('drop table dbo.'+fn.table_name+';') as drop_st
from filenames fn
OUTER APPLY
(select STRING_AGG(CONVERT(NVARCHAR(MAX),('Col'+cast(ORDINAL_POSITION as varchar(3))+'="Col'+cast(ORDINAL_POSITION as varchar(3))+'" text')),CHAR(13)) col_type from INFORMATION_SCHEMA.COLUMNS sc WHERE sc.table_name=fn.table_name ) cl
where 1=1

Καλησπέρα κύριε στράτο, θα ήθελα να σας ρωτήσω μιας και μιλάτε για την sql server ο καλύτερος μέγιστος δυνατός τρόπος για να διαβάζουμε Excel/CSV/TXT και να εισάγουμε τις εγγραφές σε πίνακα θεωρείται ότι είναι ένας από τους παραπάνω ή είναι το SSIS? ευχαριστώ.
Είναι ανά περίπτωση και τι θες να κάνεις. Π.χ αν θες να γεμίζεις ένα template έτοιμο με μορφοποιήσεις, χρώματα και logo γίνεται είτε με αυτόν τον τρόπο είτε με Python.