

Πώς βρίσκουμε την απόδοση των υπαρχόντων Indexes και ποία καινούργια Indexes μας προτείνει ο SQL Server

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Σε προηγούμενο άρθρο είχαμε δει τι είναι τα indexes. Σε αυτό το άρθρο θα δούμε πως βρίσκουμε σε τι κατάσταση βρίσκεται ο κατακερματισμός τους, αν χρησιμοποιούντε, πότε δημιουργήθηκαν, πότε ενημερώθηκαν και αν λείπουν indexes που προτείνει ο SQL Server.
Τι πρέπει να θυμόμαστε
- Όταν ένας πίνακας έχει clustered index σημαίνει ότι τα δεδομένα αποθηκεύονται με την σειρά που είναι το πεδίο/πεδία που έχουμε ορίσει το clustered index. Ο κάθε πίνακας μπορεί να έχει ένα μόνο clustered index.
- Όταν ένας πίνακας δεν έχει clustered index ονομάζεται heap και τα δεδομένα του αποθηκεύονται άναρχα στον δίσκο. Οπότε στα αποτελέσματα του script θα δούμε ότι ο κάθε πίνακας στο index type θα έχει σίγουρα ή clustered index ή heap και ποτέ και τα δύο.
- Οι non-clustered indexes έχουν τον ρόλο του ευρετήριου, αποτελούν μια αντιγραφή των δεδομένων στα πεδία που έχει φτιαχτεί συν των πεδίων που έχουν συμπεριληφθεί (include) σε ένα διαφορετικό object.
- Τα πεδία των indexes δεν πρέπει να υπερκαλύπτονται π.χ. αν έχουμε ένα non-clustered index στους [αριθμούς τηλεφώνων] και ένα στη [περιοχή] , [στον αριθμό τηλεφώνων] το πρώτο index δεν χρειάζεται οπότε θα πρέπει να διαγραφεί. (για λόγους συντήρησης τους και μνήμης)
- Το μέγεθος του πίνακα (είτε clustered είτε heap) και του κάθε non-clustered index μπορούμε να το μετρήσουμε και σε pages. Το κάθε page είναι 8KB, οπότε άμα το πολλαπλασιάσουμε με το πλήθος τους βρίσκουμε το μέγεθος του πίνακα / non-clustered index.
- Όσο αλλάζουν οι εγγραφές ενός πίνακα κατακερματίζονται δηλαδή χάνεται η σειρά τους αυτό ονομάζεται fragmentation. Για να μειωθεί θα πρέπει να κάνουμε το index rebuild είτε reorganize αν το ποσοστό fragmentation είναι μικρό.
- Όσο από λιγότερα pages αποτελείται είναι λογικό να έχει πιο εύκολα μεγαλύτερο fragmentation αλλά δεν επηρεάζεται τόσο η απόδοση. π.χ. Αν σε πίνακα με ένα page προστεθεί ένα δεύτερο θα έχουμε κατευθείαν 50% fragmentation.
- Κάποια dynamic views που μας παρέχουν τις πληροφορίες που χρειαζόμαστε, αδειάζουν κάθε φορα που γίνεται επανεκκίνηση το SQL Server service.
Πώς βρίσκουμε το fragmentation των indexes
Με το παρακάτω script που έχω φτιάξει βρίσκουμε γρήγορα το fragmentation του κάθε index με σειρά pages. Μπορούμε αφαιρόντας από σχόλιο το –and dbtables.[name] in (‘car_calc’) να βρούμε μόνο για συγκεκριμένο πίνακα:
select distinct
dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
clustertype.index_type_desc as 'IndexType',
clustertype.avg_fragmentation_in_percent,
clustertype.page_count,
clustertype.index_type_desc
FROM sys.indexes AS dbindexes
INNER JOIN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) as clustertype ON clustertype.[object_id] = dbindexes.[object_id] AND clustertype.index_id = dbindexes.index_id
INNER JOIN sys.tables dbtables on dbtables.[object_id] = clustertype.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
WHERE 1=1
--and dbindexes.[name] is not NULL
--and clustertype.index_type_desc = 'NONCLUSTERED INDEX'
--and dbtables.[name] in ('car_calc')
ORDER BY page_count desc,dbtables.name desc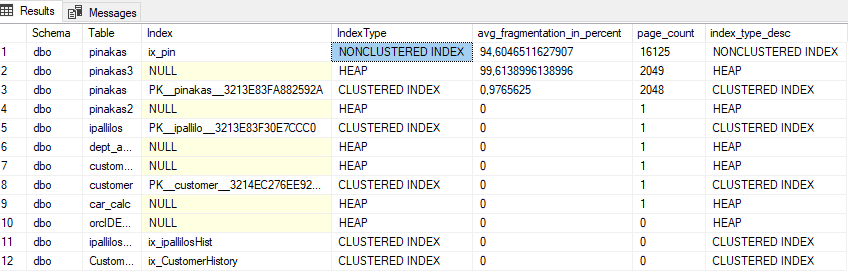
Indexes που προτείνει ο SQL Server
Ο SQL Server όταν βλέπει ότι κάποια query χρειάζονται index σε κάποιο πεδίο που χρησιμοποιήται προτείνει την δημιουργία τους. Επειδή δεν έχει πάντα δίκαιο είναι απαραίτητη η αξιολόγηση τους. Με το παρακάτω script μας εμφανίζονται όσους προτείνει:
SELECT db.[name] AS [DatabaseName]
,id.[object_id] AS [ObjectID]
,OBJECT_NAME(id.[object_id], db.[database_id]) AS [ObjectName]
,id.[statement] AS [FullyQualifiedObjectName]
,id.[equality_columns] AS [EqualityColumns]
,id.[inequality_columns] AS [InEqualityColumns]
,id.[included_columns] AS [IncludedColumns]
,gs.[unique_compiles] AS [UniqueCompiles]
,gs.[user_seeks] AS [UserSeeks]
,gs.[user_scans] AS [UserScans]
,gs.[last_user_seek] AS [LastUserSeekTime]
,gs.[last_user_scan] AS [LastUserScanTime]
,gs.[avg_total_user_cost] AS [AvgTotalUserCost] -- Average cost of the user queries that could be reduced by the index in the group.
,gs.[avg_user_impact] AS [AvgUserImpact] -- The value means that the query cost would on average drop by this percentage if this missing index group was implemented.
,gs.[system_seeks] AS [SystemSeeks]
,gs.[system_scans] AS [SystemScans]
,gs.[last_system_seek] AS [LastSystemSeekTime]
,gs.[last_system_scan] AS [LastSystemScanTime]
,gs.[avg_total_system_cost] AS [AvgTotalSystemCost]
,gs.[avg_system_impact] AS [AvgSystemImpact] -- Average percentage benefit that system queries could experience if this missing index group was implemented.
,gs.[user_seeks] * gs.[avg_total_user_cost] * (gs.[avg_user_impact] * 0.01) AS [IndexAdvantage]
,'CREATE INDEX [IX_' + OBJECT_NAME(id.[object_id], db.[database_id]) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(id.[equality_columns], ''), ', ', '_'), '[', ''), ']', '') + CASE
WHEN id.[equality_columns] IS NOT NULL
AND id.[inequality_columns] IS NOT NULL
THEN '_'
ELSE ''
END + REPLACE(REPLACE(REPLACE(ISNULL(id.[inequality_columns], ''), ', ', '_'), '[', ''), ']', '') + '_' + LEFT(CAST(NEWID() AS [nvarchar](64)), 5) + ']' + ' ON ' + id.[statement] + ' (' + ISNULL(id.[equality_columns], '') + CASE
WHEN id.[equality_columns] IS NOT NULL
AND id.[inequality_columns] IS NOT NULL
THEN ','
ELSE ''
END + ISNULL(id.[inequality_columns], '') + ')' + ISNULL(' INCLUDE (' + id.[included_columns] + ')', '') AS [ProposedIndex]
,CAST(CURRENT_TIMESTAMP AS [smalldatetime]) AS [CollectionDate]
FROM [sys].[dm_db_missing_index_group_stats] gs WITH (NOLOCK)
INNER JOIN [sys].[dm_db_missing_index_groups] ig WITH (NOLOCK) ON gs.[group_handle] = ig.[index_group_handle]
INNER JOIN [sys].[dm_db_missing_index_details] id WITH (NOLOCK) ON ig.[index_handle] = id.[index_handle]
INNER JOIN [sys].[databases] db WITH (NOLOCK) ON db.[database_id] = id.[database_id]
WHERE db.[database_id] = DB_ID()
--AND OBJECT_NAME(id.[object_id], db.[database_id]) = 'YourTableName'
ORDER BY ObjectName, [IndexAdvantage] DESC
OPTION (RECOMPILE);
Πώς βρίσκουμε πότε φτιάχτηκε ο κάθε Index
Δεν μπορούμε να δούμε απευθείας πότε φτιάχτηκε ο κάθε index καθώς ο SQL Server δεν κρατάει την πληροφορία. Με το παρακάτω script βρίσκουμε πότε φτιάχτηκε ο κάθε clustered index στο πεδίο create_date και πότε έγινε modify ο πίνακας μαζί με τα indexes που μπορεί να σημαίνει δημιουργία nonclustered index στο πεδίο modify_date:
select
i.name as IndexName,
o.name as TableName,
co.[name] as ColumnName,
ic.key_ordinal as ColumnOrder,
ic.is_included_column as IsIncluded,
o.create_date,
o.modify_date
from sys.indexes i
inner join sys.objects o on i.object_id = o.object_id and o.type_desc = 'USER_TABLE'
inner join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id
inner join sys.columns co on co.object_id = i.object_id
and co.column_id = ic.column_id
where 1=1
and i.[type] in (1,2)
order by o.[name], i.[name], ic.is_included_column, ic.key_ordinal;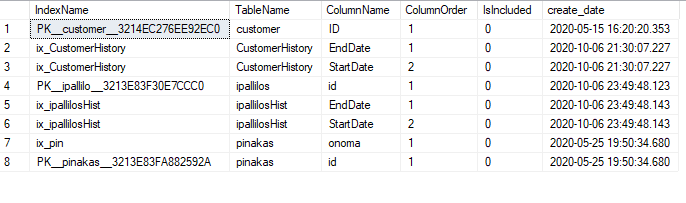
Πώς βρίσκουμε πότε έγινε ο κάθε Index τελευταία φορά Rebuild
Ο SQL Server δεν αποθηκεύει την πληροφορία του πότε έγινε rebuild τελευταία φορά ο index, όμως αποθηκεύει την τελευταία φορά που ενημερώθηκαν τα στατιστικά. Στην default συμπεριφορά κάθε φορά που εκτελείται index rebuild εκτελείται και το statistics update οπότε γνωρίζοντας την ημερομηνία του δεύτερου γνωρίζουμε και του πρώτου.
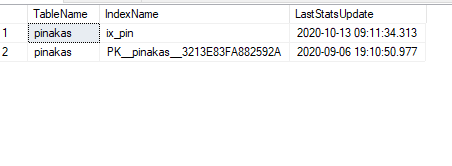
Με το παρακάτω script βρίσκουμε την ημερομηνία των τελευταίων στατιστικών:
select OBJECT_NAME(object_id) [TableName],
name [IndexName],
stats_date(object_id, stats_id) [LastStatsUpdate]
from sys.stats
where name not like '_WA%'
--and stats_date(object_id, stats_id) IS NOT NULL
and OBJECTPROPERTY(object_id, 'IsMSShipped') = 0
--and OBJECT_NAME(object_id) = 'pinakas'
ORDER BY LastStatsUpdate DESC
Πώς βρίσκουμε πόσο χρησιμοποιείται ο κάθε Index (Unused Indexes)
Κάποιες φορές δημιουργούμε indexes που δεν χρησιμοποιούνται, αυτό έχει σαν αποτέλεσμα να καταλαμβάνουν χώρο από την μνήμη (RAM) του SQL Server χωρίς όφελος, επίσης ο αυξημένος αριθμός indexes καθυστερεί τα inserts/deletes/updates αφού η ενημέρωση πρέπει να γίνει και σε αυτούς όπως και την συντήρηση τους.
Με το παρακάτω script μπορούμε να δούμε για το κάθε index πόσες φορές προσπελάστηκε, με ποιόν τρόπο και πότε ήταν η τελευταία φορά:
SELECT
DB_NAME([database_id]) as DatabaseName,
s.name As TSchema,
o.name AS TableName
, i.name AS IndexName
, dm_ius.user_seeks AS UserSeeks
, dm_ius.user_scans AS UserScans
, dm_ius.user_lookups AS UserLookups
, dm_ius.user_updates AS UserUpdates
,o.create_date
,m.modify_date
,'drop index ['+s.name +'].[' +o.name+ '].[' + i.name +'];' as DropCommand
FROM sys.dm_db_index_usage_stats dm_ius WITH (NOLOCK)
INNER JOIN sys.indexes i ON i.index_id = dm_ius.index_id
AND dm_ius.OBJECT_ID = i.OBJECT_ID
INNER JOIN sys.objects o ON dm_ius.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.schemas s ON o.schema_id = s.schema_id
WHERE OBJECTPROPERTY(dm_ius.OBJECT_ID,'IsUserTable') = 1
AND dm_ius.database_id = DB_ID()
AND dm_ius.database_id > 4
AND i.type_desc = 'nonclustered'
AND i.is_primary_key = 0
AND i.is_unique_constraint = 0
/*
AND
dm_ius.user_lookups = 0
AND
dm_ius.user_seeks = 0
AND
dm_ius.user_scans = 0
*/
ORDER BY dm_ius.user_updates desc
Πώς βρίσκουμε τα Duplicate Indexes
Όσο φτιάχνουμε καινούργια indexes υπάρχει περίπτωση να δημιουργήσουμε διπλότυπα indexes είτε indexes που κάνουν overlapping την ίδιες κολώνες με την ίδια σειρά. Αυτό έχει σαν αποτέλεσμα να καθυστερούν τα insert, updates και deletes όπως και το maintenance των indexes. Οπότε θα πρέπει να βρούμε αυτά τα indexes και να τα διαγράψουμε.
Με το παρακάτω query θα βρούμε όλη την πληροφορία που χρειαζόμαστε:
CREATE TABLE #duplindex
(
[database_name] NVARCHAR(255),
[schema_name] NVARCHAR(255),
[table_name] NVARCHAR(255),
[index_name] NVARCHAR(255),
[key_column_list] NVARCHAR(max),
[include_column_list] NVARCHAR(max),
[is_disabled] NVARCHAR(10)
)
DECLARE @DatabaseID as INT;
DECLARE @DatabaseName as NVARCHAR(250);
DECLARE @DatabaseCursor as CURSOR;
DECLARE @dxml NVARCHAR(MAX);
DECLARE @dbody NVARCHAR(MAX);
SET @DatabaseCursor = CURSOR FOR
SELECT name, database_id
FROM sys.databases WITH (NOLOCK) where name not in ( 'master', 'model', 'msdb', 'tempdb')
and state_desc='ONLINE'
and is_read_only = 0;
OPEN @DatabaseCursor;
FETCH NEXT FROM @DatabaseCursor INTO @DatabaseName, @DatabaseID;
WHILE @@FETCH_STATUS = 0
BEGIN
EXECUTE ('USE [' + @DatabaseName + ']'+'
;WITH CTE_INDEX_DATA AS (
SELECT TABLE_DATA.object_id,
INDEX_DATA.index_id,
SCHEMA_DATA.name AS schema_name,
TABLE_DATA.name AS table_name,
INDEX_DATA.name AS index_name,
STUFF((SELECT '', '' + COLUMN_DATA_KEY_COLS.name + '' '' + CASE WHEN INDEX_COLUMN_DATA_KEY_COLS.is_descending_key = 1 THEN ''DESC'' ELSE ''ASC'' END -- Include column order (ASC / DESC)
FROM sys.tables AS T WITH (NOLOCK)
INNER JOIN sys.indexes INDEX_DATA_KEY_COLS
ON T.object_id = INDEX_DATA_KEY_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_KEY_COLS
ON INDEX_DATA_KEY_COLS.object_id = INDEX_COLUMN_DATA_KEY_COLS.object_id
AND INDEX_DATA_KEY_COLS.index_id = INDEX_COLUMN_DATA_KEY_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_KEY_COLS
ON T.object_id = COLUMN_DATA_KEY_COLS.object_id
AND INDEX_COLUMN_DATA_KEY_COLS.column_id = COLUMN_DATA_KEY_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_KEY_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_KEY_COLS.index_id
AND INDEX_COLUMN_DATA_KEY_COLS.is_included_column = 0
ORDER BY INDEX_COLUMN_DATA_KEY_COLS.key_ordinal
FOR XML PATH('''')), 1, 2, '''') AS key_column_list ,
STUFF(( SELECT '', '' + COLUMN_DATA_INC_COLS.name
FROM sys.tables AS T WITH (NOLOCK)
INNER JOIN sys.indexes INDEX_DATA_INC_COLS WITH (NOLOCK)
ON T.object_id = INDEX_DATA_INC_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_INC_COLS WITH (NOLOCK)
ON INDEX_DATA_INC_COLS.object_id = INDEX_COLUMN_DATA_INC_COLS.object_id
AND INDEX_DATA_INC_COLS.index_id = INDEX_COLUMN_DATA_INC_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_INC_COLS WITH (NOLOCK)
ON T.object_id = COLUMN_DATA_INC_COLS.object_id
AND INDEX_COLUMN_DATA_INC_COLS.column_id = COLUMN_DATA_INC_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_INC_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_INC_COLS.index_id
AND INDEX_COLUMN_DATA_INC_COLS.is_included_column = 1
ORDER BY INDEX_COLUMN_DATA_INC_COLS.key_ordinal
FOR XML PATH('''')), 1, 2, '''') AS include_column_list,
INDEX_DATA.is_disabled -- Check if index is disabled before determining which dupe to drop (if applicable)
FROM sys.indexes INDEX_DATA WITH (NOLOCK)
INNER JOIN sys.tables TABLE_DATA WITH (NOLOCK)
ON TABLE_DATA.object_id = INDEX_DATA.object_id
INNER JOIN sys.schemas SCHEMA_DATA WITH (NOLOCK)
ON SCHEMA_DATA.schema_id = TABLE_DATA.schema_id
WHERE TABLE_DATA.is_ms_shipped = 0
AND INDEX_DATA.type_desc IN (''NONCLUSTERED'', ''CLUSTERED'')
)
Insert into #duplindex
SELECT db_name(), DUPE1.schema_name, DUPE1.table_name,DUPE1.index_name,DUPE1.key_column_list,DUPE1.include_column_list,DUPE1.is_disabled
FROM CTE_INDEX_DATA DUPE1
WHERE EXISTS
(SELECT * FROM CTE_INDEX_DATA DUPE2
WHERE DUPE1.schema_name = DUPE2.schema_name
AND DUPE1.table_name = DUPE2.table_name
AND (DUPE1.key_column_list LIKE LEFT(DUPE2.key_column_list, LEN(DUPE1.key_column_list)) OR DUPE2.key_column_list LIKE LEFT(DUPE1.key_column_list, LEN(DUPE2.key_column_list)))
AND DUPE1.index_name <> DUPE2.index_name) OPTION (MAXDOP 4)
')
FETCH NEXT FROM @DatabaseCursor INTO @DatabaseName, @DatabaseID;
END
CLOSE @DatabaseCursor;
DEALLOCATE @DatabaseCursor;
select
database_name as 'Database Name',
schema_name as 'Schema',
table_name as 'Table',
index_name as 'Index Name',
key_column_list as 'Key Column List',
include_column_list as 'Include Column List',
is_disabled as 'Is Disabled'
from #duplindex
DROP TABLE #duplindex