

Πώς αποθηκεύονται οι βάσεις δεδομένων και τι είναι τα indexes

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Έχουμε δει τι είναι μια σχεσιακή βάση δεδομένων (relational database) και ότι οι οντότητές μας είναι λογικά αντικείμενα που ονομάζονται πίνακες.
Πώς όμως αποθηκεύονται “φυσικά” σε ένα RDBMS (σύστημα διαχείρισης σχεσιακών βάσεων δεδομένων);
Οι πίνακες σαν objects αποθηκεύονται και αυτά σε ένα σκληρό δίσκο.
H πληροφορία τους ως το πιο κατακερματισμένο κομμάτι της ονομάζετε page (σελίδα). Πολλές page μαζί αποτελούν ένα extent.
Θα πρέπει να αναφερθεί ότι στην Oracle το μέγεθος της σελίδας δεν είναι σταθερό, ενώ στον SQL Server είναι 8Κ. Όπως επίσης στην Oracle ένα σύνολο από extents ονομάζεται segment.
Τι είναι ο query optimizer και το execution plan;
Αποθηκεύοντας τεράστιο πλήθος δεδομένων σε σκληρούς δίσκους η ανάκτηση συγκεκριμένης πληροφορίας γίνεται χρονοβόρα με υψηλό κόστος πόρων (resources).
Τα RDBMS έχουν ένα εργαλείο που λειτουργεί όπως ένα GPS.
Μπορεί να βρει τα μονοπάτια που πρέπει να ακολουθήσει, ώστε να φτάσει στα δεδομένα και να επιλέξει τον πιο γρήγορο τρόπο με το λιγότερο κόστος.
Αυτό το εργαλείο ονομάζεται query optimizer και ο αντίστοιχος χάρτης του ονομάζεται execution plan (πλάνο).
Τι είναι τα indexes και τα statistics;
Οι βασικοί σύμμαχοι του query optimizer είναι τα indexes και τα στατιστικά. Ως Index ορίζουμε μία δομή αποθήκευσης στον σκληρό δίσκο συσχετισμένη με έναν πίνακα ή view.
Τα στατιστικά είναι ένα σύνολο στατιστικών πληροφοριών για ένα πίνακα ή view όπως πλήθος εγγραφών, μέσος όρος μήκους του κάθε πεδίου, πόσα πεδία είναι κενά(null), κλπ.
Καθώς γίνονται αλλαγές στη βάση, τα δεδομένα στο δίσκο αλλάζουν. Έτσι οι δύο αυτές δομές χρειάζονται συντήρηση. Τα indexes defragmentation/rebuild και τα statistics update.
Oι πίνακες / views που έχουν αλλαγές κατά πάνω από 10% και δεν έχει γίνει update στα στατιστικά τους ονομάζονται stale.
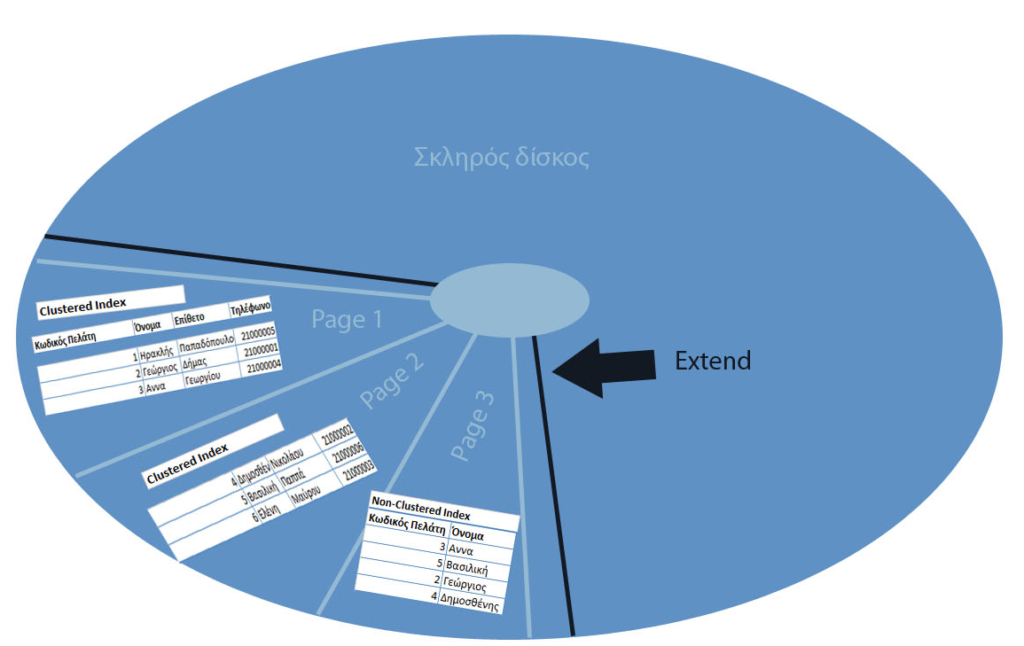
Τι διαφορά έχουν τα clustered με τα non-clustered indexes;
Clustered index
Clustered index είναι το index που έχει τα δεδομένα του σε σειρά βασισμένη στο πεδίο που έχει οριστεί, συνήθως είναι το primary key (είναι η default συμπεριφορά στον SQL Server) και μπορεί να υπάρχει μόνο ένα ανά οντότητα.
Οι πίνακες / views που δεν έχουν clustered index ονομάζονται heap. Με τη χρήση τους τα δεδομένα αποθηκεύονται φυσικά στον δίσκο όχι άναρχα αλλά σε σειρά.
Για παράδειγμα σε ένα πίνακα που είχε ορισμένο σαν primary key τον αριθμό ταυτότητας, όσοι αριθμοί ξεκινούσαν από Α θα βρισκόντουσαν σε γειτονικά blocks.
Οπότε θα ήτανε πολύ εύκολο για το RDBMS να απαντήσει σε ένα ερώτημα, όπως φέρε μου όσους πολίτες που η ταυτότητα του ξεκινάει από Α.
Σαν αποτέλεσμα όταν μιλάμε για clustered index, μιλάμε για τον τρόπο που είναι αποθηκευμένα τα actual data των εγγραφών στο σκληρό δίσκο.
Tα πεδία κλειδιά των indexes είτε είναι clustered είτε non-clustered οργανώνονται συνήθως με την αρχιτεκτονική του b+ tree. Αυτό συμβαίνει ώστε να είναι πιο γρήγορα και πιο εύκολα προσπελάσιμα.
Non-clustered index
Non-clustered index σε αντίθεση με τους clustered indexes είναι ξεχωριστά από τα δεδομένα των εγγραφών της οντότητας και λειτουργούν σαν ένα ευρετήριο.
Περιέχουν ένα πεδίο ή και πολλά (πχ Επίθετο, Όνομα) που του έχουμε ορίσει να φτιαχτεί. Μέσω pointers (row locators) δείχνουν στη γραμμή που βρίσκεται ολόκληρη η εγγραφή του πίνακα/view ή στο primary key του clustered index αν δεν είναι heap.
Για παράδειγμα αν φτιάξουμε ένα non-clustered index στο πεδίο Όνομα του πίνακα πελάτης. Θα μπορούμε να φέρουμε εύκολα τους πελάτες που το όνομα τους είναι Κώστας ή ξεκινάνε από Κ.
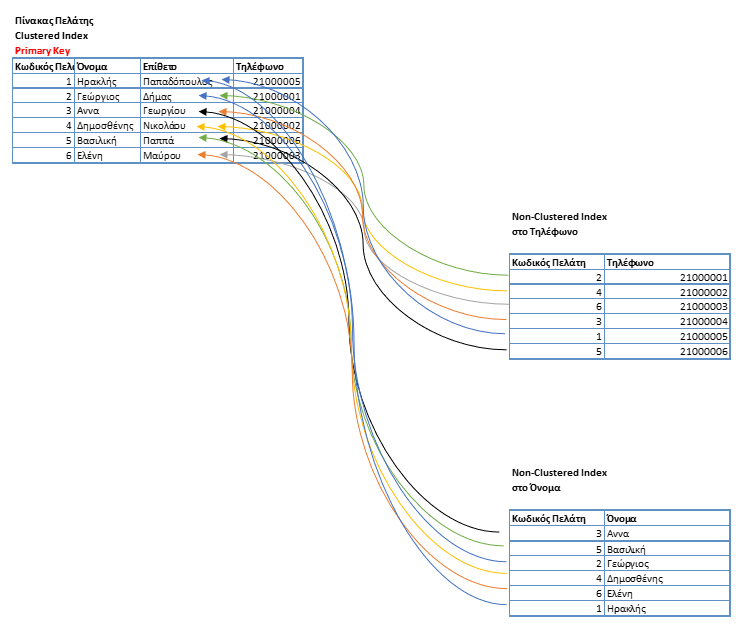
Μέσα από το παράδειγμα βλέπουμε ότι ο πραγματικός πίνακας (με Clustered Index) είναι στη σειρά αναλόγως του κωδικού πελάτη που είναι το πεδίο που έχει φτιαχτεί ο index.
Στους δύο Non-Clustered τα δεδομένα είναι σε σειρά κατά διαφορετικό πεδίο, το ένα ως προς το τηλέφωνο και το άλλο ως προς το όνομα.
Αν όμως σε κάποιο από αυτά χρειαστούμε έξτρα πληροφορία εκτός του Non-Clustered Index του πχ Επίθετο. Θα πρέπει να γίνει ένα key lookup προς τον πίνακα του πελάτη ώστε να φέρει την τιμή για το καθένα από αυτά.
Αυτό συνήθως είναι μια χρονοβόρα διαδικασία προς τη βάση.
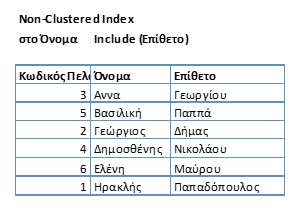
Στη περίπτωση που θέλουμε τα δεδομένα μας να είναι σε σειρά(sorted) με ένα πεδίο, αλλά να περιέχει και πληροφορία από τα υπόλοιπα δεδομένα που υπάρχουν στον πίνακα χωρίς lookup, τότε κάνουμε το πεδίο αυτό include.
Για παράδειγμά στο Non-Clustered Index στο Όνομα προσθέτουμε (include) σαν πληροφορία το επίθετο.
Ποιο είναι το drawback;
Κλείνοντας θα πρέπει να αναφερθεί το γιατί αφού τα indexes είναι χρήσιμα, να μην κάνουμε πολλά non-clustered indexes στα περισσότερα πεδία ή να μην κάνουμε include όλες τις εγγραφές.
- Κάθε φορά που πραγματοποιείτε μια συναλλαγή στον πίνακα / view ενημερώνονται και τα indexes του. Πράγμα που σημαίνει καθυστερήσεις στη πραγματοποίηση των συναλλαγών.
- Περισσότερο χώρο στον δίσκο: ένα non-clustered index που έχει include όλα τα πεδία του πίνακα το μέγεθος του θα είναι περίπου όσο είναι ολόκληρος ο πίνακας / clustered index.
- Memory pressure στην RAM: όσα περισσότερα έχουμε, τόσο περισσότερη πληροφορία θα μαζεύετε κασαρισμένη στην μνήμη (cache buffer pool). Πράγμα που σημαίνει μεγαλύτερη απάιτηση σε μνήμη που η έλειψη της οδηγεί poor performance.
Αγαπητέ συνάδελφε διαβάζω τα post σου και είναι αρκετά χρήσιμα και σε ευχαριστούμε για αυτά.
Μια μικρή διόρθωση: “Αυτό το εργαλείο ονομάζετε query optimizer και ο αντίστοιχος χάρτης του ονομάζετε execution plan (πλάνο).” > ονομάζεται
Fixed 🙂