

How databases are stored and what indexes are

Certifications:

We have seen what a relational database is and that our entities are logical objects called tables.
But how are they stored “physically” in an RDBMS (relational database management system)?
Tables like objects are also stored on a hard disk.
You call their information the most fragmented part of it page (page). Several pages together form one extent.
It should be mentioned that in Oracle the page size is not constant, while in SQL Server it is 8K. As also in Oracle a set of extents is called segment.
What is query optimizer and execution plan?
By storing a huge amount of data on hard drives, the recovery of specific information becomes time-consuming with a high cost of resources.
The RDBMS they have a tool that works like a GPS.
It can find the paths to follow to get to the data and choose the fastest way with the least cost.
This tool is called query optimizer and its corresponding map is called execution plan.
What are indexes and statistics?
The main allies of the query optimizer are the indexes and statistics. As Index we define a storage structure on the hard disk associated with a table or view.
Statistics are a set of statistical information for a table or view such as number of records, average length of each field, how many fields are empty (null), etc.
As changes are made to the database, the data on disk changes. So these two structures need maintenance. The indexes defragmentation/rebuild and statistics update.
The tables / views that have changes over 10% and their statistics have not been updated are called stale.
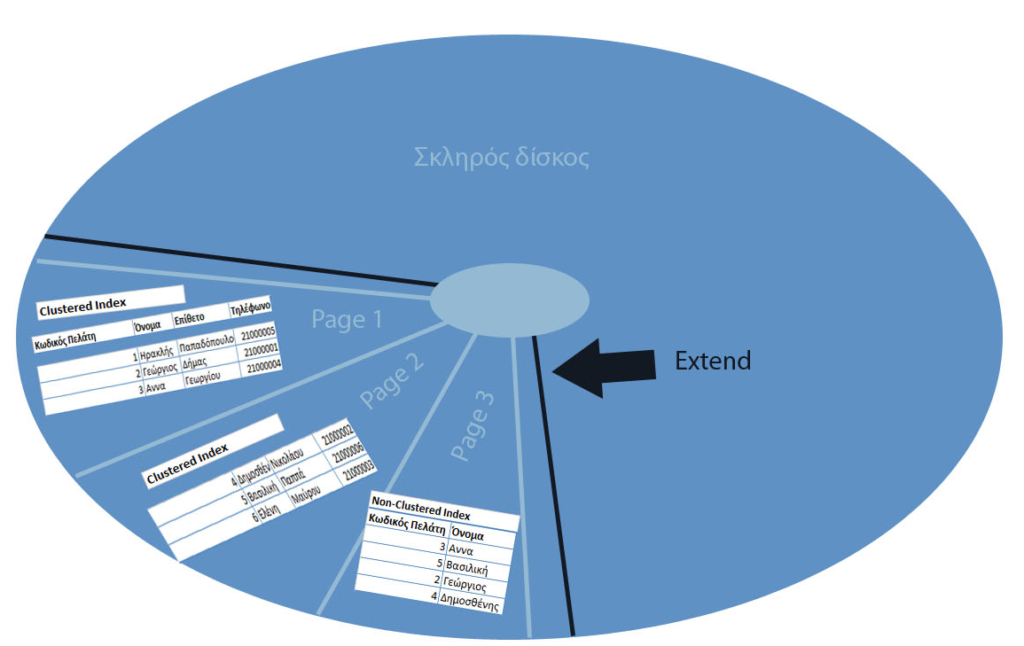
What is the difference between clustered and non-clustered indexes?
Clustered index
Clustered index is the index that has its data in order based on the field defined, usually the primary key (it is the default behavior in SQL Server) and there can only be one per entity.
Tables / views that do not have a clustered index are called heap. By using them the data is physically stored on the disk not randomly but in order.
For example, in a table that had the identity number defined as a primary key, those numbers starting with A would be in adjacent blocks.
So it would be very easy for the RDBMS to answer a query like bring me as many citizens whose ID starts with A.
As a result, when we talk about a clustered index, we are talking about the way the actual data of the records are stored on the hard disk.
The key fields of indexes, whether clustered or non-clustered, are usually organized with its architecture b+ tree. This is so that they are faster and easier to access.
Non-clustered index
Non-clustered index unlike clustered indexes they are separate from the entity record data and function like an index.
They contain one or several fields (eg Surname, First Name) that we have defined to be created. Through pointers (row locators) they point to the line where the entire record of the table/view is located or to the primary key of the clustered index if it is not a heap.
For example if we create a non-clustered index on the Name field of the customer table. We will be able to easily bring customers whose name is Kostas or whose name starts with K.
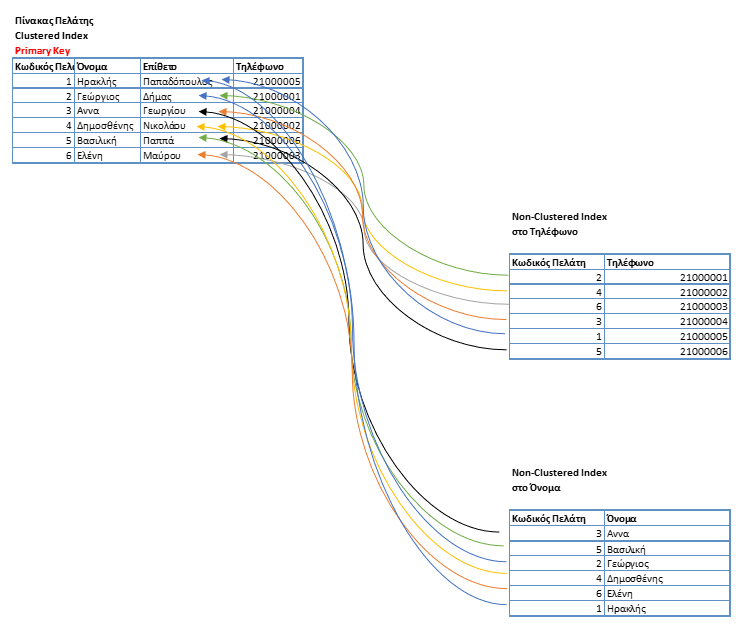
Through the example we see that the real table (with Clustered Index) is in order according to the customer code which is the field where the index is created.
In the two Non-Clustered the data is ordered by a different field, one by phone and the other by name.
However, if in any of them we need extra information outside of the Non-Clustered Index of eg Surname. A key should be made lookup to the client table to fetch the value for each of them.
This is usually a time consuming process towards the base.
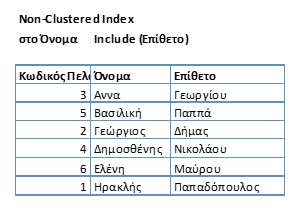
In the event that we want our data to be in order (sorted) with a field, but also contains information from the rest of the data in the table without lookup, then we make this field include.
For example in the Non-Clustered Index in the Name we add (include) as information the adjective.
What is the drawback?
In closing, it should be mentioned why, since indexes are useful, not to make many non-clustered indexes in most fields or not to include all records.
- Every time you perform a transaction on the table / view, its indexes are also updated. Which means delays in carrying out the transactions.
- More disk space: a non-clustered index that has included all the fields of the table, its size will be approximately the size of the entire table / clustered index.
- Memory pressure on RAM: the more we have, the more information you will collect crammed into memory (cache buffer pool). Which means a greater demand on memory, the lack of which leads to poor performance.
Dear colleague, I read your posts and they are quite useful and we thank you for them.
A small correction: "You call this tool a query optimizer and its corresponding map you call an execution plan." > is called
Fixed 🙂