

How we find the performance of existing Indexes and which new Indexes SQL Server recommends

Certifications:

In a previous article we saw what are indexes. In this article we will see how to find the status of their hash, if you are using them, when they were created, when they were updated and if they are missing indexes recommended by SQL Server.
What should we remember?
- When a table has clustered index means that the data is stored in the order that is the field/fields that we have defined the clustered index. Each table can have just one clustered index.
- When a table does not have a clustered index it is called heap and its data is stored out of order on disk. So in the results of the script we will see that each table in the index type will definitely have either a clustered index or a heap and never both.
- The non-clustered indexes they have his role index, are a copy of the data in the fields it has been made plus the fields they have included to a different object.
- The index fields must not overlap, e.g. if we have a non-clustered index at [phone numbers] and one in [area] , [at phone no] the first index is not needed so it should be deleted. (for their maintenance and memory reasons)
- The size of the table (either clustered or heap) and of each non-clustered index can also be measured in pages. Each page is 8KB, so if we multiply it by the number of them we find the size of the table / non-clustered index.
- As the records of a table change, they are fragmented, that is, their order is lost, this is called fragmentation. To reduce it, we should do the index rebuild or reorganize if the fragmentation rate is small.
- As it consists of fewer pages, it makes sense that it will more easily have greater fragmentation but performance is not affected as much. e.g. If a second page is added to a table with one page, we will directly have 50% fragmentation.
- Some dynamic views that provide us with the information we need, they empty every time the SQL Server service is restarted.
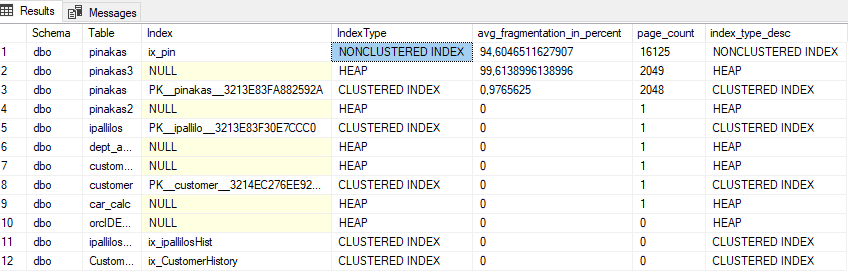
How do we find the fragmentation of indexes
With the following script that I have made, we quickly find the fragmentation of each index with a series of pages. We can remove it from comment –and dbtables.[name] in ('car_calc') to find only for a specific table:
select distinct
dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
clustertype.index_type_desc as 'IndexType',
clustertype.avg_fragmentation_in_percent,
clustertype.page_count,
clustertype.index_type_desc
FROM sys.indexes AS dbindexes
INNER JOIN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) as clustertype ON clustertype.[object_id] = dbindexes.[object_id] AND clustertype.index_id = dbindexes.index_id
INNER JOIN sys.tables dbtables on dbtables.[object_id] = clustertype.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
WHERE 1=1
--and dbindexes.[name] is not NULL
--and clustertype.index_type_desc = 'NONCLUSTERED INDEX'
--and dbtables.[name] in ('car_calc')
ORDER BY page_count desc,dbtables.name desc
Indexes recommended by SQL Server
When SQL Server sees that some queries need an index in some field that is used, it suggests creating them. Because it is not always fair, it is necessary to evaluate them. With the following script, those who recommend us are shown:
SELECT db.[name] AS [DatabaseName]
,id.[object_id] AS [ObjectID]
,OBJECT_NAME(id.[object_id], db.[database_id]) AS [ObjectName]
,id.[statement] AS [FullyQualifiedObjectName]
,id.[equality_columns] AS [EqualityColumns]
,id.[inequality_columns] AS [InEqualityColumns]
,id.[included_columns] AS [IncludedColumns]
,gs.[unique_compiles] AS [UniqueCompiles]
,gs.[user_seeks] AS [UserSeeks]
,gs.[user_scans] AS [UserScans]
,gs.[last_user_seek] AS [LastUserSeekTime]
,gs.[last_user_scan] AS [LastUserScanTime]
,gs.[avg_total_user_cost] AS [AvgTotalUserCost] -- Average cost of the user queries that could be reduced by the index in the group.
,gs.[avg_user_impact] AS [AvgUserImpact] -- The value means that the query cost would on average drop by this percentage if this missing index group was implemented.
,gs.[system_seeks] AS [SystemSeeks]
,gs.[system_scans] AS [SystemScans]
,gs.[last_system_seek] AS [LastSystemSeekTime]
,gs.[last_system_scan] AS [LastSystemScanTime]
,gs.[avg_total_system_cost] AS [AvgTotalSystemCost]
,gs.[avg_system_impact] AS [AvgSystemImpact] -- Average percentage benefit that system queries could experience if this missing index group was implemented.
,gs.[user_seeks] * gs.[avg_total_user_cost] * (gs.[avg_user_impact] * 0.01) AS [IndexAdvantage]
,'CREATE INDEX [IX_' + OBJECT_NAME(id.[object_id], db.[database_id]) + '_' + REPLACE(REPLACE(REPLACE(ISNULL(id.[equality_columns], ''), ', ', '_'), '[', ''), ']', '') + CASE
WHEN id.[equality_columns] IS NOT NULL
AND id.[inequality_columns] IS NOT NULL
THEN '_'
ELSE ''
END + REPLACE(REPLACE(REPLACE(ISNULL(id.[inequality_columns], ''), ', ', '_'), '[', ''), ']', '') + '_' + LEFT(CAST(NEWID() AS [nvarchar](64)), 5) + ']' + ' ON ' + id.[statement] + ' (' + ISNULL(id.[equality_columns], '') + CASE
WHEN id.[equality_columns] IS NOT NULL
AND id.[inequality_columns] IS NOT NULL
THEN ','
ELSE ''
END + ISNULL(id.[inequality_columns], '') + ')' + ISNULL(' INCLUDE (' + id.[included_columns] + ')', '') AS [ProposedIndex]
,CAST(CURRENT_TIMESTAMP AS [smalldatetime]) AS [CollectionDate]
FROM [sys].[dm_db_missing_index_group_stats] gs WITH (NOLOCK)
INNER JOIN [sys].[dm_db_missing_index_groups] ig WITH (NOLOCK) ON gs.[group_handle] = ig.[index_group_handle]
INNER JOIN [sys].[dm_db_missing_index_details] id WITH (NOLOCK) ON ig.[index_handle] = id.[index_handle]
INNER JOIN [sys].[databases] db WITH (NOLOCK) ON db.[database_id] = id.[database_id]
WHERE db.[database_id] = DB_ID()
--AND OBJECT_NAME(id.[object_id], db.[database_id]) = 'YourTableName'
ORDER BY ObjectName, [IndexAdvantage] DESC
OPTION (RECOMPILE);

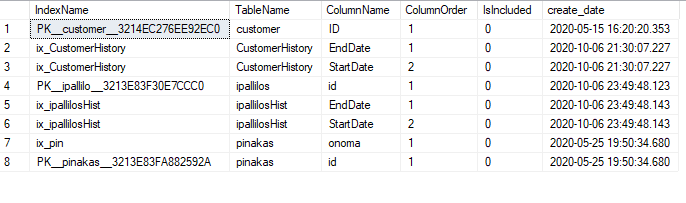
How do we find when each Index was created?
We cannot see directly when each index was created as SQL Server does not keep the information. With the following script we find when each one was made clustered index in the field created_date and when was the table modified along with the indexes which may mean creation nonclustered index in the field modify_date:
select
i.name as IndexName,
o.name as TableName,
co.[name] as ColumnName,
ic.key_ordinal as ColumnOrder,
ic.is_included_column as IsIncluded,
o.create_date,
o.modify_date
from sys.indexes i
inner join sys.objects o on i.object_id = o.object_id and o.type_desc = 'USER_TABLE'
inner join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id
inner join sys.columns co on co.object_id = i.object_id
and co.column_id = ic.column_id
where 1=1
and i.[type] in (1,2)
order by o.[name], i.[name], ic.is_included_column, ic.key_ordinal;
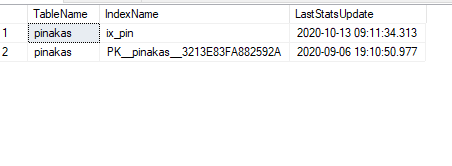
How do we find when each Index was last Rebuilt?
SQL Server does not store the information of when the index was last rebuilt, but it stores the last time the statistics were updated. In the default behavior, every time an index rebuild is performed, the statistics update is also performed, so knowing the date of the second, we also know the date of the first.
With the following script we find the date of the last statistics:
select OBJECT_NAME(object_id) [TableName],
name [IndexName],
stats_date(object_id, stats_id) [LastStatsUpdate]
from sys.stats
where name not like '_WA%'
--and stats_date(object_id, stats_id) IS NOT NULL
and OBJECTPROPERTY(object_id, 'IsMSShipped') = 0
--and OBJECT_NAME(object_id) = 'pinakas'
ORDER BY LastStatsUpdate DESC
How we find how much each Index is used (Unused Indexes)
Sometimes we create indexes that are not used, this has the result that they occupy space from the memory (RAM) of the SQL Server without benefit, also the increased number of indexes delays the inserts/deletes/updates since the update must be done in them as well their maintenance.
With the following script we can see for each index how many times it was accessed, in what way and when was the last time:
SELECT
DB_NAME([database_id]) as DatabaseName,
s.name As TSchema,
o.name AS TableName
, i.name AS IndexName
, dm_ius.user_seeks AS UserSeeks
, dm_ius.user_scans AS UserScans
, dm_ius.user_lookups AS UserLookups
, dm_ius.user_updates AS UserUpdates
,o.create_date
,m.modify_date
,'drop index ['+s.name +'].[' +o.name+ '].[' + i.name +'];' as DropCommand
FROM sys.dm_db_index_usage_stats dm_ius WITH (NOLOCK)
INNER JOIN sys.indexes i ON i.index_id = dm_ius.index_id
AND dm_ius.OBJECT_ID = i.OBJECT_ID
INNER JOIN sys.objects o ON dm_ius.OBJECT_ID = o.OBJECT_ID
INNER JOIN sys.schemas s ON o.schema_id = s.schema_id
WHERE OBJECTPROPERTY(dm_ius.OBJECT_ID,'IsUserTable') = 1
AND dm_ius.database_id = DB_ID()
AND dm_ius.database_id > 4
AND i.type_desc = 'nonclustered'
AND i.is_primary_key = 0
AND i.is_unique_constraint = 0
/*
AND
dm_ius.user_lookups = 0
AND
dm_ius.user_seeks = 0
AND
dm_ius.user_scans = 0
*/
ORDER BY dm_ius.user_updates desc

How we find Duplicate Indexes
While creating new indexes, there is a chance to create duplicate indexes or indexes that overlap the same columns in the same order. This has the effect of delaying inserts, updates and deletes as well as index maintenance. So we should find these indexes and delete them.
With the following query we will find all the information we need:
CREATE TABLE #duplindex
(
[database_name] NVARCHAR(255),
[schema_name] NVARCHAR(255),
[table_name] NVARCHAR(255),
[index_name] NVARCHAR(255),
[key_column_list] NVARCHAR(max),
[include_column_list] NVARCHAR(max),
[is_disabled] NVARCHAR(10)
)
DECLARE @DatabaseID as INT;
DECLARE @DatabaseName as NVARCHAR(250);
DECLARE @DatabaseCursor as CURSOR;
DECLARE @dxml NVARCHAR(MAX);
DECLARE @dbody NVARCHAR(MAX);
SET @DatabaseCursor = CURSOR FOR
SELECT name, database_id
FROM sys.databases WITH (NOLOCK) where name not in ( 'master', 'model', 'msdb', 'tempdb')
and state_desc='ONLINE'
and is_read_only = 0;
OPEN @DatabaseCursor;
FETCH NEXT FROM @DatabaseCursor INTO @DatabaseName, @DatabaseID;
WHILE @@FETCH_STATUS = 0
BEGIN
EXECUTE ('USE [' + @DatabaseName + ']'+'
;WITH CTE_INDEX_DATA AS (
SELECT TABLE_DATA.object_id,
INDEX_DATA.index_id,
SCHEMA_DATA.name AS schema_name,
TABLE_DATA.name AS table_name,
INDEX_DATA.name AS index_name,
STUFF((SELECT '', '' + COLUMN_DATA_KEY_COLS.name + '' '' + CASE WHEN INDEX_COLUMN_DATA_KEY_COLS.is_descending_key = 1 THEN ''DESC'' ELSE ''ASC'' END -- Include column order (ASC / DESC)
FROM sys.tables AS T WITH (NOLOCK)
INNER JOIN sys.indexes INDEX_DATA_KEY_COLS
ON T.object_id = INDEX_DATA_KEY_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_KEY_COLS
ON INDEX_DATA_KEY_COLS.object_id = INDEX_COLUMN_DATA_KEY_COLS.object_id
AND INDEX_DATA_KEY_COLS.index_id = INDEX_COLUMN_DATA_KEY_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_KEY_COLS
ON T.object_id = COLUMN_DATA_KEY_COLS.object_id
AND INDEX_COLUMN_DATA_KEY_COLS.column_id = COLUMN_DATA_KEY_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_KEY_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_KEY_COLS.index_id
AND INDEX_COLUMN_DATA_KEY_COLS.is_included_column = 0
ORDER BY INDEX_COLUMN_DATA_KEY_COLS.key_ordinal
FOR XML PATH('''')), 1, 2, '''') AS key_column_list ,
STUFF(( SELECT '', '' + COLUMN_DATA_INC_COLS.name
FROM sys.tables AS T WITH (NOLOCK)
INNER JOIN sys.indexes INDEX_DATA_INC_COLS WITH (NOLOCK)
ON T.object_id = INDEX_DATA_INC_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_INC_COLS WITH (NOLOCK)
ON INDEX_DATA_INC_COLS.object_id = INDEX_COLUMN_DATA_INC_COLS.object_id
AND INDEX_DATA_INC_COLS.index_id = INDEX_COLUMN_DATA_INC_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_INC_COLS WITH (NOLOCK)
ON T.object_id = COLUMN_DATA_INC_COLS.object_id
AND INDEX_COLUMN_DATA_INC_COLS.column_id = COLUMN_DATA_INC_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_INC_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_INC_COLS.index_id
AND INDEX_COLUMN_DATA_INC_COLS.is_included_column = 1
ORDER BY INDEX_COLUMN_DATA_INC_COLS.key_ordinal
FOR XML PATH('''')), 1, 2, '''') AS include_column_list,
INDEX_DATA.is_disabled -- Check if index is disabled before determining which dupe to drop (if applicable)
FROM sys.indexes INDEX_DATA WITH (NOLOCK)
INNER JOIN sys.tables TABLE_DATA WITH (NOLOCK)
ON TABLE_DATA.object_id = INDEX_DATA.object_id
INNER JOIN sys.schemas SCHEMA_DATA WITH (NOLOCK)
ON SCHEMA_DATA.schema_id = TABLE_DATA.schema_id
WHERE TABLE_DATA.is_ms_shipped = 0
AND INDEX_DATA.type_desc IN (''NONCLUSTERED'', ''CLUSTERED'')
)
Insert into #duplindex
SELECT db_name(), DUPE1.schema_name, DUPE1.table_name,DUPE1.index_name,DUPE1.key_column_list,DUPE1.include_column_list,DUPE1.is_disabled
FROM CTE_INDEX_DATA DUPE1
WHERE EXISTS
(SELECT * FROM CTE_INDEX_DATA DUPE2
WHERE DUPE1.schema_name = DUPE2.schema_name
AND DUPE1.table_name = DUPE2.table_name
AND (DUPE1.key_column_list LIKE LEFT(DUPE2.key_column_list, LEN(DUPE1.key_column_list)) OR DUPE2.key_column_list LIKE LEFT(DUPE1.key_column_list, LEN(DUPE2.key_column_list)))
AND DUPE1.index_name <> DUPE2.index_name) OPTION (MAXDOP 4)
')
FETCH NEXT FROM @DatabaseCursor INTO @DatabaseName, @DatabaseID;
END
CLOSE @DatabaseCursor;
DEALLOCATE @DatabaseCursor;
select
database_name as 'Database Name',
schema_name as 'Schema',
table_name as 'Table',
index_name as 'Index Name',
key_column_list as 'Key Column List',
include_column_list as 'Include Column List',
is_disabled as 'Is Disabled'
from #duplindex
DROP TABLE #duplindex