

How to export bulk data from Oracle database using Oracle Data Pump (expdp)

Certifications:

Many times we will need to keep the data of tables and of metadata (packages, procedures, functions, etc.) them so that we can then import them into the same or a different system. The data can be extracted using the tool Oracle Data Pump Export (expdp) while the introduction by using it Oracle Data Pump Import (impdp).
The extraction of this information can be said to constitute one "logical backup" of this data but in no case is it considered to replace a database backup.
How Oracle Data Pump Export (expdp) works
Calling it Data Pump Export (expdp) a job is created and starts running whose job is to export the data of the tables and their metadata to physical files located on the server called dump files.
We can refine what will be exported and how by using parameters. These parameters can be declared either on the command line or in a separate parameter file.
The preliminary work
For starters we'll need a user that has the role DATAPUMP_EXP_FULL_DATABASE or also DATAPUMP_IMP_FULL_DATABASE if we enter data with the same user. Alternatively we can use user defined SYSDBA although not recommended.
grant DATAPUMP_EXP_FULL_DATABASE to stratos;
We'll need one too logical directory which will point to a physical directory on the server. In this directory will be exported the dump files of the export or import that we have defined in the parameters to use it.
create directory fakelos as '/home/oracle/Documents';
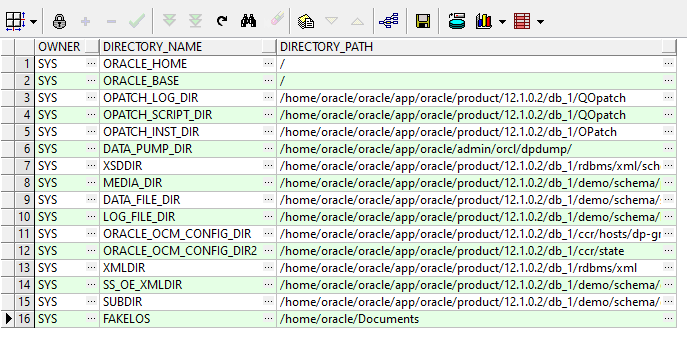
To see the existing directories:
select owner,directory_name,directory_path from all_directories;
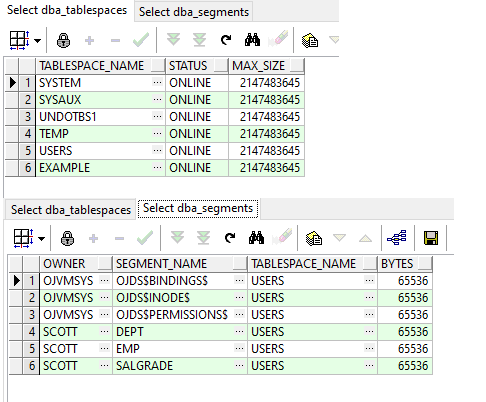
To see the existing tablespaces and the tables they contain:
select tablespace_name,status,max_size from dba_tablespaces; select owner,segment_name,tablespace_name,bytes from dba_segments where tablespace_name = 'USERS' and segment_type = 'TABLE';
The example
The simplest example we can try is to export a small array. The only parameters needed are the logical directory we made earlier, the name of the dumpfile and the name of the table (we have set metrics and logfile to be exported to the same directory as well).
[opc@dp-gr ~]$ expdp stratos/stratos directory=FAKELOS dumpfile=pinakas2_dept.DMP logfile=export.log metrics=y TABLES = SCOTT.DEPT
Alternatively if we would like to use a parameter file. We would create a file named e.g. params.par which would contain all the parameters one below the other and we would set it with the parameter in expdp parfile.
directory=FAKELOS
dumpfile=pinakas2_dept.DMP
logfile=export.log
metrics=y
TABLES = SCOTT.DEPT[opc@dp-gr ~]$ expdp stratos/stratos parfile=/home/oracle/Documents/params.par
[opc@dp-gr ~]$ expdp stratos/stratos directory=FAKELOS dumpfile=pinakas_dept.DMP logfile=export.log metrics=y TABLES = SCOTT.DEPT
...
Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real
Total estimation using BLOCKS method: 64 KB
Processing object type TABLE_EXPORT/TABLE/TABLE
Completed 1 TABLE objects in 10 seconds
Processing object type TABLE_EXPORT/TABLE/INDEX/INDEX
Completed 1 INDEX objects in 3 seconds
Processing object type TABLE_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Completed 1 CONSTRAINT objects in 4 seconds
Processing object type TABLE_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Completed 1 INDEX_STATISTICS objects in 0 seconds
Processing object type TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Completed 1 TABLE_STATISTICS objects in 2 seconds
Processing object type TABLE_EXPORT/TABLE/STATISTICS/MARKER
Completed 1 MARKER objects in 25 seconds
. . exported "SCOTT"."DEPT" 6.023 KB 4 rows in 0 seconds
Completed 1 TABLE_EXPORT/TABLE/TABLE_DATA objects in 0 seconds
Master table "STRATOS"."SYS_EXPORT_TABLE_01" successfully loaded/unloaded
******************************************************************************
Dump file set for STRATOS.SYS_EXPORT_TABLE_01 is:
/home/oracle/Documents/pinakas_dept.DMP
Job "STRATOS"."SYS_EXPORT_TABLE_01" successfully completed
To see the Data Pump jobs in progress:
select * from dba_datapump_jobs

We also have the possibility to do it by having the name of the job (using the previous query). attach in another window and see lots of useful information like completion rate and bytes written.
[opc@dp-gr ~]$ expdp stratos/stratos attach=SYS_EXPORT_TABLE_01
Alternatively if we use the sysdba account.
[oracle@dp-gr opc]$ expdp "'/as sysdba'" attach=SYS_EXPORT_TABLE_01
Export> status
Job: SYS_EXPORT_TABLE_01
Operation: EXPORT
Mode: TABLE
State: COMPLETING
Bytes Processed: 6,169
Percent Done: 100
Current Parallelism: 1
Job Error Count: 0
Dump File: /home/oracle/Documents/pinakas_dept.DMP
bytes written: 49,152
Worker 1 Status:
Instance ID: 1
Instance name: ORCL
Host name: dp-gr
Process Name: DW00
State: WORK WAITING
This information is updated by writing the command status.
If for some reason the job stops, e.g. there is not enough space, a message will also appear in the following dynamic view. If we fix it in a reasonable time it will continue automatically.
select name,status,timeout,error_number,error_msg from DBA_RESUMABLE;
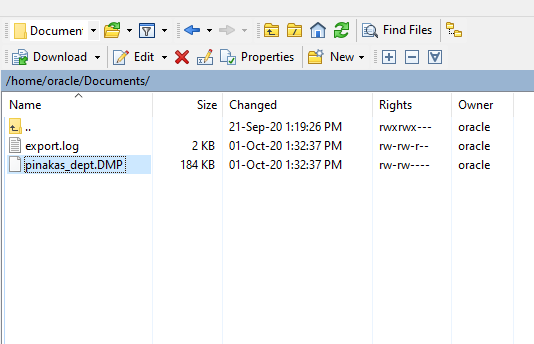
The result
After the task is completed, we will see that the dump file and the log file have been created in the physical directory.
Useful parameters
Let's also look at some useful parameters that we can set in Data Pump Export so that we have better control over the data we will export.
FULL
With this parameter we can export the entire base.
FULL=y
TABLESPACES
With this parameter we can export selected tablespaces.
TABLESPACES=USERS
TABLES
With this parameter we can export selected tables.
TABLES=SCOTT.DEPT,SCOTT.SALGRADE
DUMPFILE
With this parameter we can give a name to the dumpfile that Data Pump Export will produce. However, with the characters "%u" several sequentially numbered files (up to 99) can be created.
dumpfile=export_pinaka%u.DMP
FILESIZE
With this parameter we define the maximum size of each dump file. We can e.g. let's set it to 1 GB.
filesize=1024m
SCHEMES
With this parameter we can export entire specific user.
schemas=SCOTT
EXCLUDE
With this parameter we can exclude specific objects such as schema, tables, etc.
EXCLUDE=SCHEMA:"=SYS"
INCLUDE
Accordingly, with this parameter we can add specific objects such as schema, tables, etc.
INCLUDE=SCHEMA:"=SCOTT" INCLUDE=TABLE:"IN (select table_name from dba_tables where table_name like 'DEP%')"
QUERY
With this parameter we can write queries to extract specific data only from one table.
query=SCOTT.SALGRADE:"where HISAL > '2000'"
CONTENT
We use this parameter when we want to export only the data or only metadata.
content=data_only content=metadata_only
PARALLEL
With this parameter we define the simultaneous parallel channels that will perform the task. We usually define the number of CPU cores by two.
Parallel=8
FLASHBACK_TIME
According to undo_retention and its size undo tablespace using technology flashback query we can export data with past tense.
FLASHBACK_TIME="TO_TIMESTAMP('20-09-2020 10:00:00', 'DD-MM-YYYY HH24:MI:SS')"
LOGFILES
In this parameter we define the name of the logfile that will contain information about the process.
CLUSTER
With this parameter we define whether Data Pump will use other nodes in Oracle Real Application Clusters (Oracle RAC) by creating workers on them as well.
METRICS
With this parameter, additional information is displayed in the log file.
metrics=y
VERSION
With this parameter we can export data that may be in an older version, e.g. 11.2 in order to import them into a newer e.g. 19.3. If we have not exported them with this parameter, an error will appear during the import process.
version=11.2
In the article we analyzed its process Oracle Data Pump Export (expdp). In the next article we will see how to import this dump file with the process Data Pump Import (impdp). .