

Γιατί να κάνουμε partition έναν πίνακα και πως γίνεται στον SQL Server

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Όπως γνωρίζουμε μια σχεσιακή βάση δεδομένων αποτελείται κυρίως από οντότητες που ονομάζονται πίνακες.
Οι πίνακες δεν έχουν κάποιο λογικό όριο στο μέγεθος που μπορούν να φτάσουν. Yπάρχουν περιπτώσεις που το μέγεθος τους μπορεί να γίνει μη διαχειρίσιμο.
Που ξεκινάει το πρόβλημα;
Όταν ένας πίνακας μεγαλώνει πολύ, αυξάνονται οι χρόνοι για κάποιο μελλοντικό rebuild των indexes, όπως και των στατιστικών.
Σαν να μην έφτανε αυτό ένας μεγάλος πίνακας θα καθυστερεί τη βάση κάτα την εκτέλεση backup.
Τέλος σε ένα πολύ μεγάλο πίνακα οι χρόνοι για να γίνουν seek εγγραφές θα είναι επίσης αυξημένοι. Αυτό έχει σαν αποτέλεσμα αρκετά ανεβασμένες I/O διεργασίες στους φυσικούς δίσκους.
Κάπου εκεί έρχεται το table partitioning
Το table partitioning είναι μια τεχνολογία στα RDBMS(σχεσιακά συστήματα διαχείρισης βάσεων δεδομένων), που επιτρέπει ένας πίνακας να διαιρείτε φυσικά σε διάφορα filegroups. Αυτά μπορούν να βρίσκονται σε διαφορετικούς δίσκους.
Ο διαχωρισμός σε διαφορετικά filegroups γίνεται επιλέγοντας κάποιο πεδίο που συνηθίζεται να είναι τύπου ημερομηνίας.
Πως λειτουργεί το table partitioning;
Στον SQL Server το πρώτο πράγμα που κάνουμε είναι να φτιάξουμε καινούργια filegroups, αναλόγως πως θέλουμε να υλοποιήσουμε το partitioning(π.χ. ανά έτος , τρίμηνο, μήνα, κλπ). Αυτό το βήμα δεν είναι απαραίτητο καθώς μπορούμε να κάνουμε χρήση το υπάρχων Primary filegroup για όλα τα partitions.
Έπειτα θα πρέπει να φτιάξουμε ένα partition function που θέτουμε τα όρια για το καθένα π.χ. από 1/1/2016 έως 31/12/2016.
Συνεχίζουμε με την δημιουργία του partition scheme που εκεί ορίζουμε ποια filegroup ανήκουν στην ομάδα αυτή (μπορούμε να ορίσουμε και μόνο το Primary filegroup) .
Στο τέλος έχουμε δύο επιλογές. Να φτιάξουμε ένα καινούργιο πίνακα πάνω σε αυτό το scheme που θα είναι ήδη partitioned, κάνοντας copy τις εγγραφές έπειτα. Αλλιώς στον πίνακα που ήδη έχουμε και δεν είναι partitioned, να κάνουμε drop το clustered index και να φτιάξουμε καινούργιο πάνω στο partitioned scheme.
Φυσικά και οι δύο επιλογές είναι σωστές. Στη πρώτη έχουμε το μειονέκτημα ότι χρειαζόμαστε το διπλό χώρο και στη δεύτερη ότι αν πάει κάτι στραβά μπορεί να οδηγηθούμε σε restore.
Τι μας προσφέρει;
Πέρα από αυξημένες επιδόσεις (αν χρησιμοποιήσουμε διαφορετικό storage για τα datafiles που ανήκουν σε ξεχωριστά filegroups), μας δίνει τη δυνατότητα partitions παλιών ετών με την εντολή switch να τα κάνουμε archive σε ιστορικούς πίνακες. Ωστόσο η εντολή switch μας δίνει μία ακόμα δυνατότητα, να σβήνουμε instant εγραφές χωρίς να περνάνε από το transaction log κάνοντας switch το partition με τις εγραφές που θέλουμε να σβήσουμε, σε έναν staging πίνακα και μετά να τον κάνουμε truncate. Επίσης μας δίνει τη δυνατότητα filegroups προηγούμενων ετών να τα γυρίσουμε σε read-only mode. Αυτό θα μας δώσει τη δυνατότητα να μη χρειάζεται να τα παίρνουμε καθημερινά backup γλυτώνοντας συνολικό χρόνο από το backup.
Πάμε να δούμε τα βήμα βήμα τι πρέπει να κάνουμε.
Για αρχή φτιάχνομε τα filegroups από τις ιδιότητες της βάσης, επίσης θα ορίσουμε και datafiles για το κάθε filegroup:
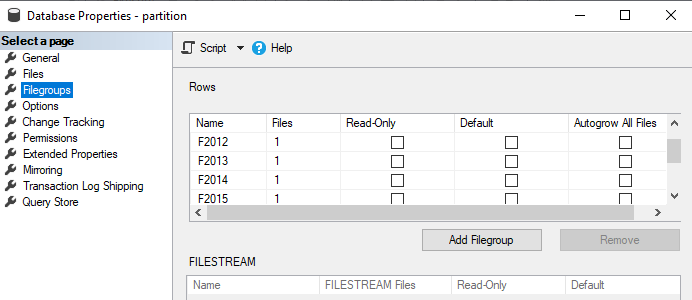
Partition function
Δημιουργούμε το partition function θέτοντας όρια από που έως που θα ορίζεται το κάθε partition. Επιλέγουμε το πεδίο που θα είναι κριτήριο, όπως συνηθίζεται είναι datetime.
Επιλέγοντας range right δηλώνουμε τιμές ως κατώτατο όριο πχ 20120101.
Αν επιλέγαμε range left (είναι το default) θα έπρεπε να ορίσουμε ανώτατα όρια αυτή την φορά πχ 20121231.
Αυτό σημαίνει ότι σε αυτό το παράδειγμα που έχει μόνο ένα μόνο όριο. Σε μια εγγραφή με ημερομηνία 20130101 θα είχαμε 2 επιλογές.
Με την επιλογή range right θα βρισκότανε στο filegroup που έχει ως κατώτατο όριο 20120101, ενώ με την επιλογή range left θα βρισκότανε στο default filegroup, αφού το ανώτατο όριο είναι 20120131.
Πάμε να φτιάξουμε ένα λειτουργικό παράδειγμα ολόκληρης την διαδικασίας:
DECLARE @boundary1 DATETIME DECLARE @boundary2 DATETIME DECLARE @boundary3 DATETIME select @boundary1='20120101', @boundary2='20130101',@boundary3='20140101' CREATE PARTITION FUNCTION tade_func(DATETIME) as range right for values (@boundary1, @boundary2, @boundary3)
Partition scheme
Συνεχίζουμε δημιουργώντας το partition scheme ορίζοντας σε ποια filegroups ανήκουν στο partition function που δημιουργήσαμε. Μπορούμε και εναλλακτικά να κάνουμε χρήση το Primary filegroup μόνο:
CREATE PARTITION SCHEME tade_scheme as partition tade_func to ( [F2000], [F2012], [F2013], [F2014] )
Δοκιμαστικά δεδομένα
Για το παράδειγμα ας φτιάξουμε έναν πίνακα δηλωμένο στο scheme που φτιάξαμε ώστε να είναι εξαρχής partitioned:
CREATE TABLE pelatis ( id INT IDENTITY(1,1), onoma varchar(20), epitheto varchar(20), create_dr DATETIME, primary key (create_dr) ) ON tade_scheme(create_dr)
Τον γεμίζουμε εγγραφές με ένα loop:
declare @i int;
set @i = 365;
while (@i>0)
begin
insert into pelatis values('Stratos','Ma',DATEADD(dd,@i,'2016/01/01'));
set @i=@i-1;
endΣε ποιο partition βρίσκονται οι εγγραφές
Με το κάτωθι query μπορούμε να δούμε σε ποιο partition είναι η κάθε εγγραφή:
select $PARTITION.tade_func(create_dr) as part_num,* from pelatis
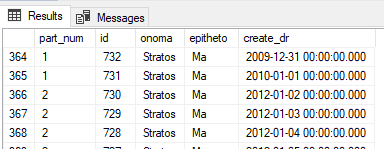
Με παρόμοιο τρόπου μπορούμε με ένα where να δούμε μόνο συγκεκριμένο partition πχ το 1:
select * from dbo.pelatis where $PARTITION.tade_func (create_dr) = 1
Πώς προσθέτουμε καινούργια partitions
Μπορούμε να προσθέσουμε filegroup για τη καινούργια χρονιά με αυτό τον τρόπο (αφού πρώτα έχουμε φτιάξει το filegroup και έχουμε ορίσει datafile):
ALTER PARTITION SCHEME tade_scheme NEXT USED [F2019]
ALTER PARTITION FUNCTION tade_func() SPLIT RANGE ('20190101')Πώς αφαιρούμε partitions
Μπορούμε να αφαιρέσουμε filegroup κάνοντας merge ώστε οι εγγραφές να πάνε στο προηγούμενο:
ALTER PARTITION FUNCTION tade_func() MERGE RANGE ('20100101')Η χρήση της εντολής SWITCH για μεταφορά εγγράφων σε ιστορικό πίνακα αλλά και άμεση διαγραφή δεδομένων
Ας φτιάξουμε έναν ιστορικό πίνακα ορισμένο σε ένα άλλο filegroup:
CREATE TABLE pelatis_hist –table creation for filegroup
(
id INT IDENTITY(1,1),
onoma varchar(20),
epitheto varchar(20),
create_dr DATETIME,
primary key (create_dr)
)
ON [prior]Με τη παρακάτω εντολή ότι ανήκει από τον πίνακα σε ιστορικές εγγραφές θα μεταφερθεί (switch) στον ιστορικό πίνακα μέσα σε ελάχιστα δευτερόλεπτα:
ALTER TABLE [dbo].[pelatis] SWITCH PARTITION 1 TO [dbo].[pelatis_hist] GO select * from pelatis_hist
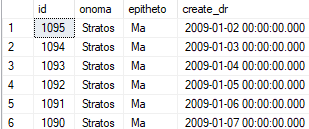
Την ίδια διαδικασία θα ακολουθούσαμε και αν απλά θέλουμε να σβήσουμε άμεσα τις εγγραφές που ανήκουν σε ένα partition. Η διαφορά είναι ότι μετά το switch του partition σε άλλον πίνακα θα τρέχαμε και την εντολή truncate η οποία θα έσβηνε ολόκληρο τον πίνακα με τις παλιές έγραφες άμεσα χωρίς να επηρεάσει τον παραγωγικό πίνακα:
truncate table [dbo].[pelatis_hist];
Πως κάνουμε μετατροπή ενός υπάρχοντα πίνακα σε partitioned χωρίς την χρήση καινούργιου πίνακα
Σε περίπτωση που θέλουμε να μετατρέψουμε τον πίνακα απευθείας από χωρίς partition σε partitioned θα πρέπει να φτιάξουμε ένα nonclustered index στο datatime πεδίο που θα γίνει το partition, να κάνουμε drop το constraint του primary key, drop το clustered index στο primary key και δημιουργία καινούργιου clustered index πάνω στο scheme που έχουμε φτιάξει (η διαδικασία ενδέχεται να πάρει πολλές ώρες):
create nonclustered index nc_pelatisDT on dbo.pelatis(create_dr) ALTER TABLE dbo.pelatis DROP CONSTRAINT [PK__pelatis___C6EE964AA629B42F] drop index [PK__pelatis___C6EE964AA629B42F] on dbo.pelatis create clustered index pk_pelatis on dbo.pelatis(create_dr) on [tade_scheme](create_dr)
Δημιουργία καινούργιου partitioned πίνακα και μεταφορά των εγγραφών από τον παλιό
Αν προτιμήσουμε τη λύση δημιουργίας πίνακα σε ήδη partitioned και την μεταφορά από τον παλιό πίνακα στο καινούργιο κάνουμε τα εξής:
Φτιάχνουμε έναν πίνακα στο scheme που φτιάξαμε για το partition:
CREATE TABLE pelatis_temp
(
id INT IDENTITY(1,1),
onoma varchar(20),
epitheto varchar(20),
create_dr DATETIME,
primary key (create_dr)
)
ON tade_scheme(create_dr)Περνάμε λίγες λίγες τις εγγραφές στον νέο πίνακα:
SET IDENTITY_INSERT pelatis_temp ON INSERT INTO pelatis_temp(id,onoma,epitheto,create_dr) SELECT * FROM pelatis p where create_dr between '2012/01/01' and '2013/01/01'
Κλείνουμε την πρόσβαση της εφαρμογής στο σημείο αυτό ώστε να μεταφέρουμε και τις τελευταίες εγγραφές που δεν έχουν μεταφερθεί:
SET IDENTITY_INSERT pelatis_temp ON INSERT INTO pelatis_Temp(id,onoma,epitheto,create_dr) SELECT * FROM pelatis p where not exists (select * from pelatis_temp t where p.id = t.id)
Κάνουμε rename τους πίνακες:
exec sp_rename 'pelatis','pelatis_old' exec sp_rename 'pelatis_temp','pelatis'
Πώς βλέπουμε τι περιέχεται στο κάθε partition
Πριν επαναφέρουμε την εφαρμογή πάμε να δούμε πως έχει γίνει ο διαχωρισμός με το κάτωθι query:
SELECT distinct
p.object_id,
o.name AS table_name,
p.partition_number,
p.rows,
au.total_pages,
au.total_pages / 128 AS total_size_mb,
au.type_desc,
p.data_compression_desc,
g.name AS [filegroup_name],
RVL.value AS left_range_boundary,
RVR.value AS right_range_boundary
--PF.[name], RV.boundary_id, RV.[value]
FROM sys.partitions AS p (nolock)
LEFT JOIN sys.objects AS o (nolock)
ON o.object_id = p.object_id
LEFT JOIN sys.indexes i (nolock)
ON p.object_id = i.object_id
AND p.index_id = i.index_id
LEFT JOIN sys.allocation_units AS au (nolock)
ON p.hobt_id = au.container_id
LEFT JOIN sys.filegroups AS g (nolock)
ON g.data_space_id = au.data_space_id
LEFT JOIN sys.partition_schemes AS PS (nolock)
ON ps.data_space_id = i.data_space_id
LEFT JOIN sys.partition_functions AS PF (nolock)
ON PF.function_id = ps.function_id
LEFT JOIN sys.partition_range_values AS RVL (nolock)
ON RVL.function_id = PF.function_id
AND RVL.boundary_id + 1 = p.partition_number
LEFT JOIN sys.partition_range_values AS RVR (nolock)
ON RVL.function_id = PF.function_id
AND RVR.boundary_id = p.partition_number
WHERE 1=1
and p.object_id in (object_id('pelatis'),object_id('pelatis_hist'))
AND p.index_id = 1
ORDER BY table_name, partition_number
GO
καλησπερα,
υπάρχει τρόπος να αυτοματικοποιήσουμε την διαδικασία του table partitioning?
ευχαριστω.
ναι υπάρχει βάζοντας σε job το creation του partition function και scheme με το range να είναι σε παράμετρο:
ALTER PARTITION FUNCTION table_function() SPLIT RANGE (@parameter);
ALTER PARTITION SCHEME table_scheme NEXT USED [PRIMARY];
easy 🙂