

Why partition a table and how to do it in SQL Server

Certifications:

As we know a relational database mainly consists of entities called tables.
Arrays have no logical limit to the size they can reach. There are cases when their size can become unmanageable.
Where does the problem start?
When a table gets too big, the times for some future increase rebuild the indexes, as well as of statistics.
As if this were not enough a large table will slow down the database during backup execution.
Finally, in a very large table the times to make seek records will also be increased. This results in quite high I/O processes on the physical disks.
That's where table partitioning comes in
Table partitioning is a technology in RDBMS(relational database management systems), which allows a table to be physically divided into several filegroups. These can be on different drives.
The separation into different filegroups it is done by selecting some field which is usually of date type.
How does table partitioning work?
In SQL Server the first thing we do is build new filegroups, depending on how we want to implement the partitioning (e.g. by year, quarter, month, etc.). This step is not necessary as we can use the existing Primary filegroup for all partitions.
Then we'll have to make one partition function that we set the limits for each e.g. from 1/1/2016 to 31/12/2016.
We continue with its creation partition scheme where we define which filegroups belong to this group (we can define only the Primary filegroup).
In the end we have two options. Let's make one new table on this scheme which will already be partitioned, copying the entries afterwards. Otherwise, in the table we already have and is not partitioned, let's do it drop the clustered index and make a new one above in the partitioned scheme.
Of course both options are correct. In the first we have the disadvantage that we need double the space and in the second that if something goes wrong we may be led to restore.
What does it offer us?
In addition to increased performance (if we use different storage for the datafiles belonging to separate filegroups), it allows us to partition old years with the command switch let's do them archive in historical tables. However the command switch gives us another option, to delete instant entries without going through the transaction log by switching the partition with the entries we want to delete, to a staging table and then doing it truncate. It also gives us the possibility of filegroups from previous years to turn them into read-only mode. This will enable us not to have to take a daily backup, saving total time from the backup.
Let's see step by step what we have to do.
First we create the filegroups from the properties of the base, we will also define datafiles for each filegroup:
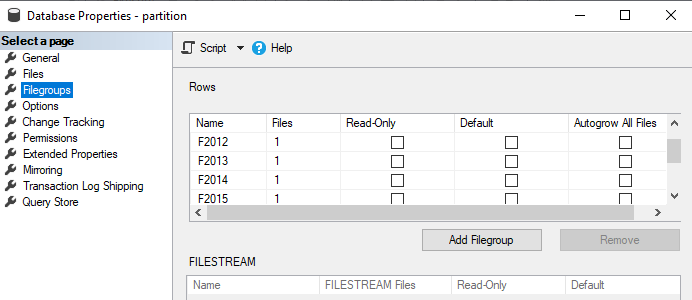
Partition function
We create it partition function setting limits from where to when each partition will be defined. We select the field that will be the criterion, as usual it is datetime.
Choosing range right we declare values as the minimum limit eg 20120101.
If we chose range left (it's the default) we should set upper limits this time eg 20121231.
This means that in this example it has only a single limit. In a record with date 20130101 we would have 2 options.
By choice range right it would be in the filegroup that has 20120101 as the minimum, while with the option range left it would be in the default filegroup, since the upper limit is 20120131.
Let's build a working example of the whole process:
DECLARE @boundary1 DATETIME DECLARE @boundary2 DATETIME DECLARE @boundary3 DATETIME select @boundary1='20120101', @boundary2='20130101',@boundary3='20140101' CREATE PARTITION FUNCTION tade_func(DATETIME) as range right for values (@boundary1, @boundary2, @boundary3)
Partition scheme
We continue by creating the partition scheme by defining which filegroups belong to the partition function we created. Alternatively, we can use the Primary filegroup only:
CREATE PARTITION SCHEME tade_scheme as partition tade_func to ( [F2000], [F2012], [F2013], [F2014] )
Test data
For example, let's create a table declared in the scheme we created so that it is partitioned from the beginning:
CREATE TABLE pelatis ( id INT IDENTITY(1,1), onoma varchar(20), epitheto varchar(20), create_dr DATETIME, primary key (create_dr) ) ON tade_scheme(create_dr)
We fill it with records with a loop:
declare @i int;
set @i = 365;
while (@i>0)
begin
insert into pelatis values('Stratos','Ma',DATEADD(dd,@i,'2016/01/01'));
set @i=@i-1;
end
In which partition are the records located?
With the following query we can see in which partition each record is:
select $PARTITION.tade_func(create_dr) as part_num,* from pelatis
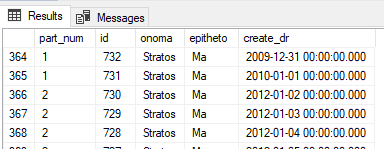
In a similar way, with a where we can see only a specific partition, e.g. 1:
select * from dbo.pelatis where $PARTITION.tade_func (create_dr) = 1
How do we add new partitions
We can add filegroup for the new year in this way (after we have first created the filegroup and defined the datafile):
ALTER PARTITION SCHEME tade_scheme NEXT USED [F2019]
ALTER PARTITION FUNCTION tade_func() SPLIT RANGE ('20190101')
How to remove partitions
We can remove a filegroup by merging so that the records go to the previous one:
ALTER PARTITION FUNCTION tade_func() MERGE RANGE ('20100101')
The use of the SWITCH command to transfer documents to a history table and also delete data immediately
Let's create a history table defined in another filegroup:
CREATE TABLE pelatis_hist –table creation for filegroup
(
id INT IDENTITY(1,1),
onoma varchar(20),
epitheto varchar(20),
create_dr DATETIME,
primary key (create_dr)
)
ON [prior]
With the following command that it belongs from the table to historical records, it will be transferred (switch) to the historical table within a few seconds:
ALTER TABLE [dbo].[pelatis] SWITCH PARTITION 1 TO [dbo].[pelatis_hist] GO select * from pelatis_hist
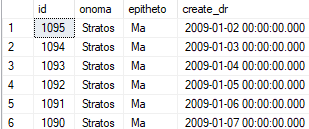
We would follow the same procedure if we simply want to immediately delete the records belonging to a partition. The difference is that after the switch of the partition to another table we would also run the command truncate which would delete the entire table of old entries immediately without affecting the productive table:
truncate table [dbo].[pelatis_hist];
How do we convert an existing table into partitioned without using a new table
In case we want to convert the table directly from unpartitioned to partitioned we will have to make one nonclustered index to datetime field where the partition will be made, let's do drop the constraint of the primary key, drop the clustered index in the primary key and creating a new one clustered index over the scheme that we have made (the process may take several hours):
create nonclustered index nc_pelatisDT on dbo.pelatis(create_dr) ALTER TABLE dbo.pelatis DROP CONSTRAINT [PK__pelatis___C6EE964AA629B42F] drop index [PK__pelatis___C6EE964AA629B42F] on dbo.pelatis create clustered index pk_pelatis on dbo.pelatis(create_dr) on [tade_scheme](create_dr)
Create a new partitioned table and transfer the records from the old one
If we prefer the solution of creating an already partitioned table and transferring it from the old table to the new one, we do the following:
We make a table in scheme which we made for the partition:
CREATE TABLE pelatis_temp
(
id INT IDENTITY(1,1),
onoma varchar(20),
epitheto varchar(20),
create_dr DATETIME,
primary key (create_dr)
)
ON tade_scheme(create_dr)
We pass the records to the new table bit by bit:
SET IDENTITY_INSERT pelatis_temp ON INSERT INTO pelatis_temp(id,onoma,epitheto,create_dr) SELECT * FROM pelatis p where create_dr between '2012/01/01' and '2013/01/01'
We close the application's access at this point in order to transfer the last records that have not been transferred:
SET IDENTITY_INSERT pelatis_temp ON INSERT INTO pelatis_Temp(id,onoma,epitheto,create_dr) SELECT * FROM pelatis p where not exists (select * from pelatis_temp t where p.id = t.id)
We rename the tables:
exec sp_rename 'pelatis','pelatis_old' exec sp_rename 'pelatis_temp','pelatis'
How to see what is contained in each partition
Before restoring the application, let's see how the separation has been done with the following query:
SELECT distinct
p.object_id,
o.name AS table_name,
p.partition_number,
p.rows,
au.total_pages,
au.total_pages / 128 AS total_size_mb,
au.type_desc,
p.data_compression_desc,
g.name AS [filegroup_name],
RVL.value AS left_range_boundary,
RVR.value AS right_range_boundary
--PF.[name], RV.boundary_id, RV.[value]
FROM sys.partitions AS p (nolock)
LEFT JOIN sys.objects AS o (nolock)
ON o.object_id = p.object_id
LEFT JOIN sys.indexes i (nolock)
ON p.object_id = i.object_id
AND p.index_id = i.index_id
LEFT JOIN sys.allocation_units AS au (nolock)
ON p.hobt_id = au.container_id
LEFT JOIN sys.filegroups AS g (nolock)
ON g.data_space_id = au.data_space_id
LEFT JOIN sys.partition_schemes AS PS (nolock)
ON ps.data_space_id = i.data_space_id
LEFT JOIN sys.partition_functions AS PF (nolock)
ON PF.function_id = ps.function_id
LEFT JOIN sys.partition_range_values AS RVL (nolock)
ON RVL.function_id = PF.function_id
AND RVL.boundary_id + 1 = p.partition_number
LEFT JOIN sys.partition_range_values AS RVR (nolock)
ON RVL.function_id = PF.function_id
AND RVR.boundary_id = p.partition_number
WHERE 1=1
and p.object_id in (object_id('pelatis'),object_id('pelatis_hist'))
AND p.index_id = 1
ORDER BY table_name, partition_number
GO

Good Evening,
is there a way to automate the table partitioning process?
thanks.
yes, it exists by putting in a job the creation of the partition function and scheme with the range as a parameter:
ALTER PARTITION FUNCTION table_function() SPLIT RANGE (@parameter);
ALTER PARTITION SCHEME table_scheme NEXT USED [PRIMARY];
easy 🙂