Πώς βλέπουμε τι εργασίες πραγματοποιεί ένα query για την ολοκλήρωση του στον SQL Server (Execution Plan Operators)

Πιστοποιήσεις:

- Πώς στέλνουμε email μέσα από Oracle Database όταν αποτύχει ένα RDBMS_SCHEDULER Job - 22 Απρίλιος 2026
- Πώς μεταφέρουμε CLOB πεδία κειμένου από Oracle Database σε SQL Server χωρίς προβλήματα - 19 Ιανουάριος 2026
- Πώς επαναφέρουμε μία Oracle Database που βρίσκεται σε archive-log mode με RMAN Restore - 1 Δεκέμβριος 2025
Για να τρέξει ένα query στον SQL Server, ο Query Optimizer δέχεται πληροφορίες όπως το query, το σχήμα της βάσης, τα στατιστικά και εξάγει τον βέλτιστο τρόπο ώστε να έχει πρόσβαση σε αυτά. Το αποτέλεσμα ονομάζεται Πλάνο ή αλλιώς Execution Plan.
Το πώς τελικά θα εκτελέσει ο SQL Server το query, περιγράφεται βήμα βήμα στο Πλάνο μέσω των Operators. Οι Operators δηλαδή περιγράφουν τη κάθε ενέργεια που πρέπει να γίνει ξεχωριστά ώστε να επιστρέψει το επιθυμητό αποτέλεσμα το query.
Πώς βλέπουμε το Execution Plan
Ο πιο εύκολος τρόπος ώστε να βλέπουμε πέρα από τα αποτελέσματα ενός query και το Execution Plan που έτρεξε, είναι να επιλέξουμε πριν την εκτέλεση του στο SQL Server Management Studio το κουμπί Include Actual Execution Plan όπως παρακάτω:
Αναλυτικά μερικοί από τους πιο συχνούς Execution Plan Operators
Table Scan Operator
Όταν βλέπουμε τον Table Scan Operator σημαίνει ότι ο Query Optimizer χρειάστηκε να διαβάσει όλες τις εγραφές του πίνακα για να επιστρέψει το επιθυμητό αποτέλεσμα:
select * from users;
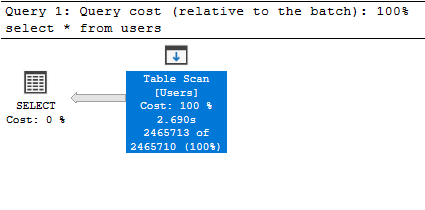
Αυτή η διαδικασία είναι απαιτητική και πρέπει να αποφεύγεται, αλλά αν για κάποιο λόγο χρειαζόμαστε όλες τις εγγραφές του πίνακα ή είναι πολύ μικρός δεν υπάρχει κάποιο πρόβλημα, σε οποιαδήποτε άλλη περίπτωση η δημιουργία ενός Index θα βοηθούσε.
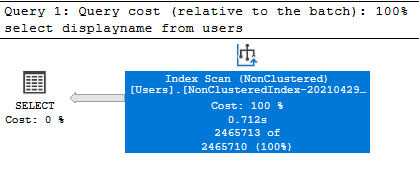
Index Scan Operator
Ο Index Scan Operator εμφανίζεται αντίστοιχα όταν ο Query Optimizer επιλέγει να διαβάσει τα δεδομένα ολόκληρου του Index. Στη περίπτωση μας έχουμε ένα Non-clustered Index στο displayname και αφού ζητάμε μόνο αυτό το πεδίο, προτιμάει να φέρει την πληροφορία από εκεί (λόγο λιγότερων pages):
select displayname from users;
Index Seek Operator
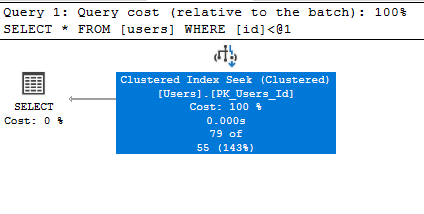
Όταν έχουμε ένα Index είτε Clustered είτε Non-clustered τα δεδομένα σε αυτό είναι ταξινομημένα, έτσι δίνει τη δυνατότητα στον Query Optimizer να ψάξει να φορτώσει μόνο τις εγραφές που πληρούν το κριτήριο που θέλουμε με τον Index Seek Operator:
select * from users where id < 100;
Key Lookup Operator
Όταν κάνουμε αναζήτηση σε πεδίο που έχει Index είναι ταξινομημένο, οπότε είναι εύκολο για τον Query Optimizer να βρεί τις τιμές που πληρούν το κριτήριο αυτό. Αν όμως ζητάμε και άλλα πεδία που δεν βρίσκονται στο Non-clustered Index (όπως στην περίπτωση μας). Tότε θα κάνει χρήση του Key Lookup Operator, που μέσω pointers που βρίσκονται στο Non-clustered Index θα ψάξει τα υπόλοιπα πεδία που βρίσκονται αποθηκευμένα στο Clustered Index του πίνακα:
select * from users where displayname like 'Joe%';
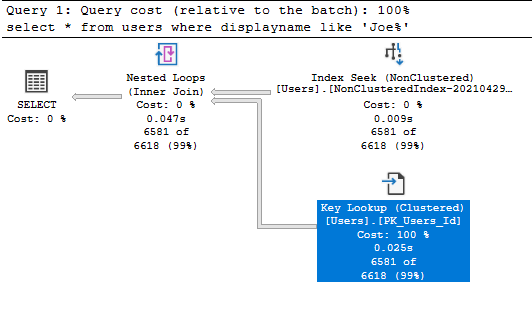
Αυτή η διαδικασία είναι ιδιαίτερα απαιτητική καθώς επαναλαμβάνεται για τη κάθε εγγραφη που πληροί το κριτήριο. Για να μην έχουμε Key Lookups θα πρέπει να προσθέσουμε με INCLUDE πάνω στο Νon-clustered Index τα πεδία που θέλουμε να εμφανίζονται στο Select.
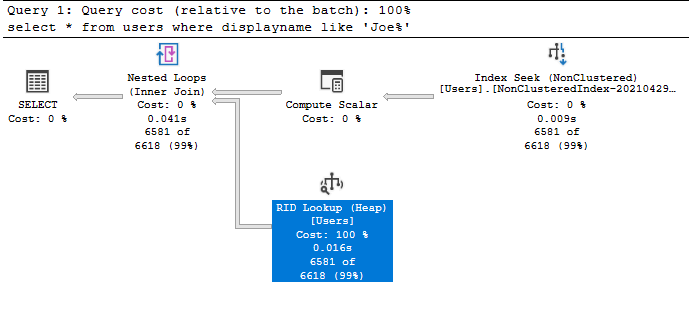
RID Lookup Operator
Το RID Lookup Operator είναι το ίδιο με το Key Lookup μόνο που εμφανίζεται στην περίπτωση που ο πίνακας μας δεν έχει Clustered Index αλλά είναι Heap δηλαδή αταξινόμητος:
ALTER TABLE [dbo].[Users] DROP CONSTRAINT [PK_Users_Id] WITH ( ONLINE = OFF ) GO select * from users where displayname like 'Joe%';
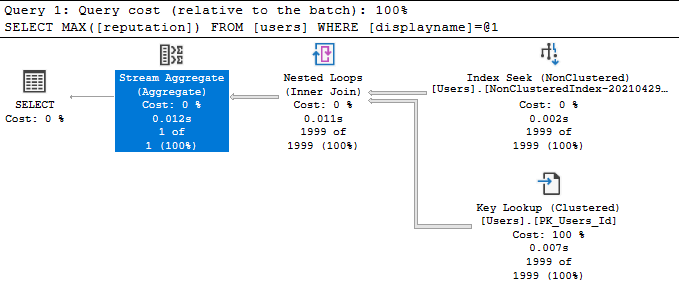
Stream Aggregate Operator
Όταν κάνουμε χρήση Aggregate Functions όπως SUM,MIN,MAX,AVG… τότε ο Stream Aggregate Operator ξεχωρίζει τις εγγραφές σε Groups και μετά κρατάει το αποτέλεσμα για το καθένα ξεχωριστά. O Stream Aggregate Operator απαιτεί στο πεδίο που γίνονται Group οι εγγραφές να είναι ταξινόμημένο, οπότε αν δεν είναι ήδη από κάποιο Index, τότε τα κάνει πρώτα Sort:
select avg(reputation) from users where displayname = 'Tom';
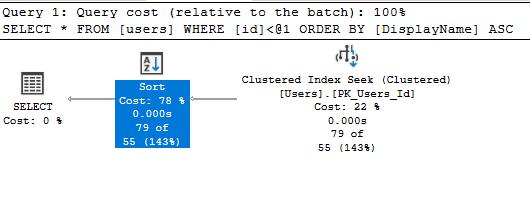
Sort Operator
Όταν θέλουμε να έχουμε τα αποτελέσματα ταξινομημένα ή να αφαιρέσουμε διπλοεγγραφές τότε θα δούμε τη χρήση του Sort Operator:
select * from users where id < 100 order by DisplayName;
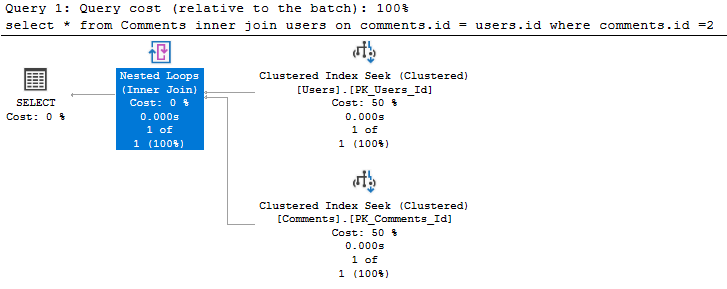
Nested Loops Operator
Όταν κάνουμε χρήση Inner και Left Joins τότε θα δούμε τα Nested Loops Operators, τα οποία αναζητούν στον εσωτερικό πίνακα την κάθε εγγραφή που πληροί τα κριτήρια του εξωτερικού πίνακα:
select * from Comments inner join users on comments.id = users.id where comments.id =2;
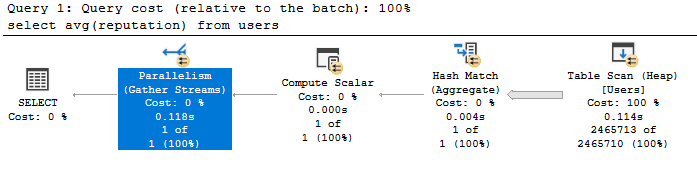
Parallelism Operator
Όταν ο Query Optimizer κρίνει ότι μπορεί και πρέπει να τρέξει το query παράλληλα, τότε το χωρίζει σε Streams και βλέπουμε τη χρήση του Parallelism Operator:
select avg(reputation) from users;