

How to setup a SQL Server Always On Availability Group for High Availability

Certifications:

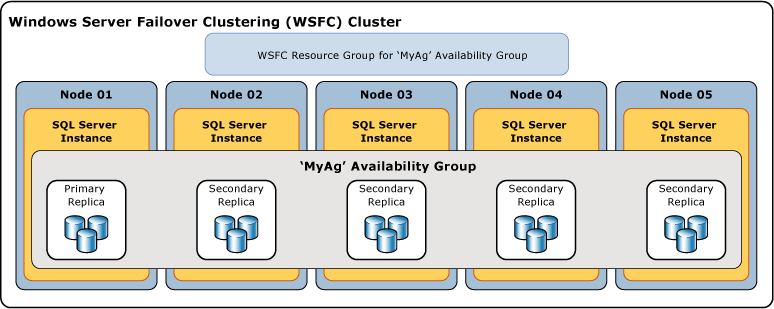
Microsoft gives us the ability to do Replicate our databases as a Group on up to eight Secondary Nodes(servers) as a solution for High Availability, Disaster Recovery or also for reading without occupying the Primary Node. This technology is called Always On Availability Group. Synchronization is done either simultaneously for High-Availability either asynchronously for Disaster Recovery. Depending on the version we have, we have different possibilities.
In this article we will see step by step how to install an Always On Availability Group and how we can monitor it.
In detail what an Always On Availability Group is and what features it provides, we can read the article here.
Prerequisites
Before we start we should have done the following actions:
- Our Nodes must have joined Active Directory Domain.
- SQL Server must have been installed on both Nodes with the user who "raises" the Service being either Active Directory User either Managed Service Account and be common in both. How to do an installation properly can be seen in the article here.
- That they can communicate with each other and that we are not interrupted by a Windows or network firewall.
The installation
Creating the Failover Cluster
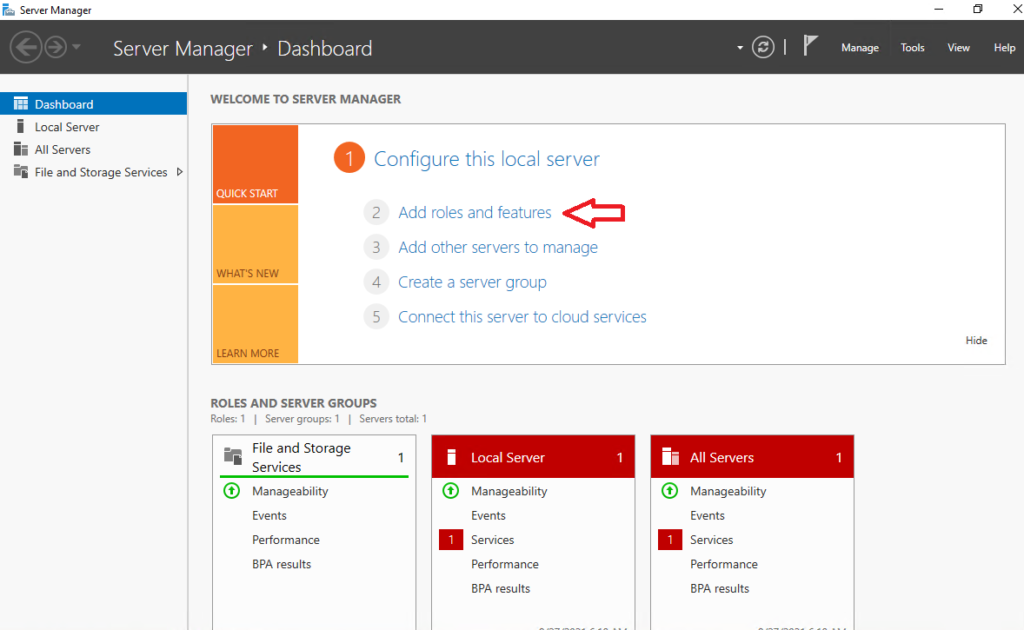
First, let's go to Server Manager of Windows Server on both Nodes and select Add roles and features:
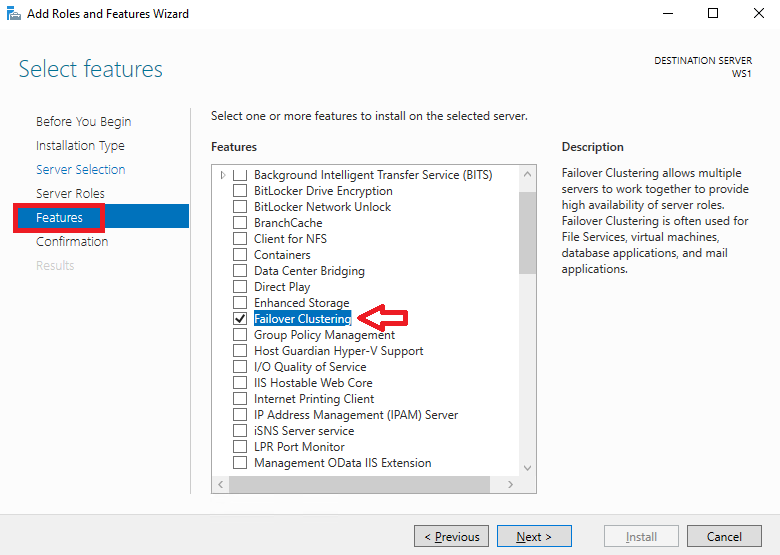
Then we go to the tab Features and we choose it Failover Clustering:
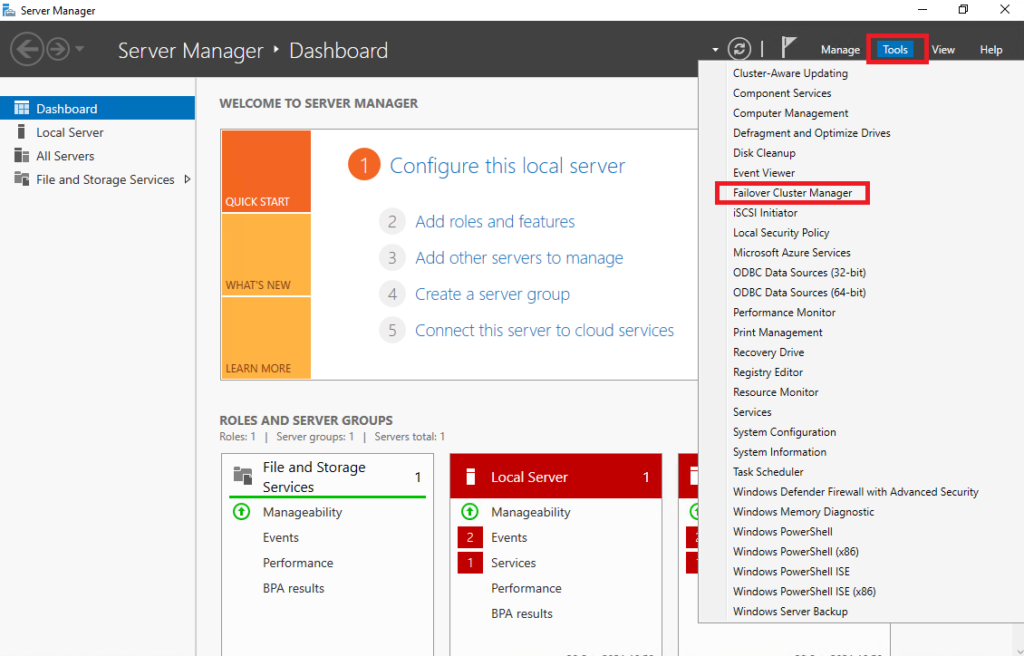
After the installation and restart on both Nodes, go to the Server Manager again on one of them and select Tools, Failover Cluster Manager:
When the Failover Cluster Manager opens, select Validate Configuration:
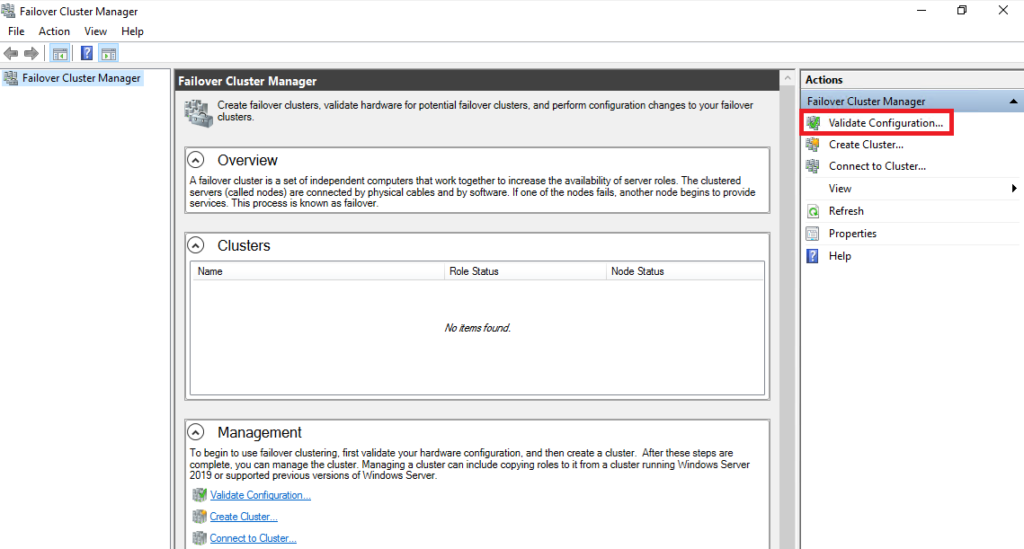
Then we add the name of each Node that we want to belong to the Cluster:
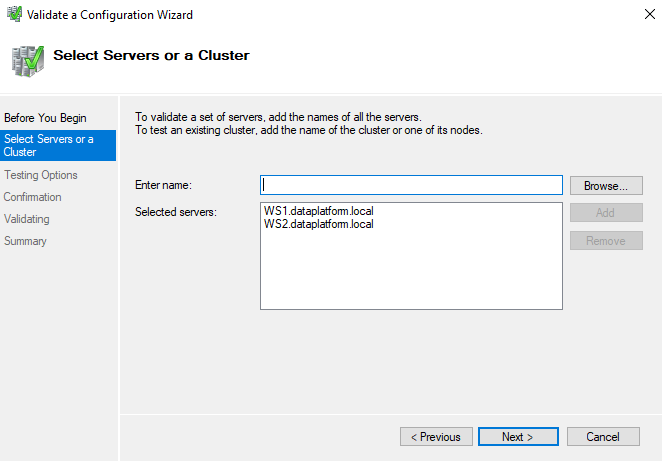
Then we choose to Validate with all tests:
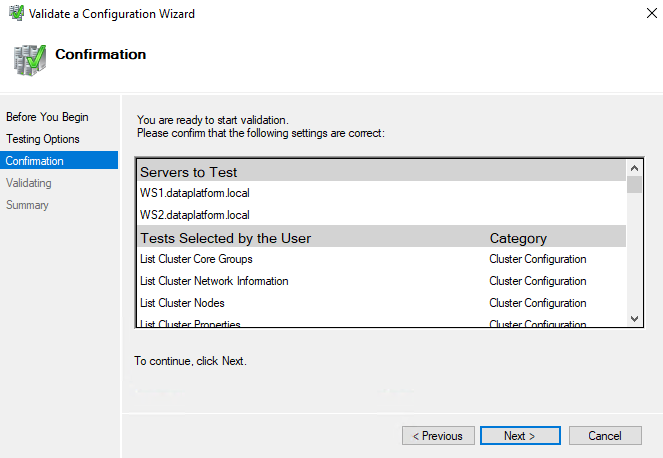
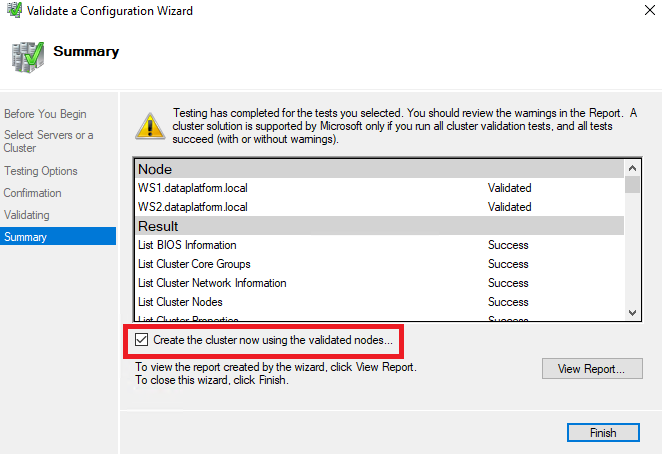
It may show us a warning as in the example we use only one network. After seeing in the report that we don't have any other important problem, we choose Create the cluster now using the validated nodes... and Finish:
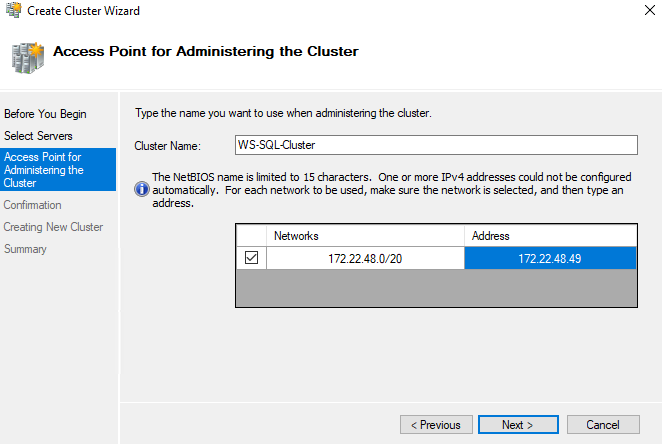
After a while it will open the Create Cluster Wizard there we will define a name for our Cluster and the IP of the Cluster which should belong to the same subnet:
Creating the Cluster Quorum
After the Cluster is created we should define one Witness in the Quorum which this can be either one file sharing, either one shared disk either one Azure Storage Account.
The job of the Witness is to communicate with both sites and in the event that one fails or the communication between them is lost, to vote for the health of the Cluster so that it continues to be up and running.
So we go to Failover Cluster Manager again, we choose More Actions and Configure Cluster Quorum Settings…:
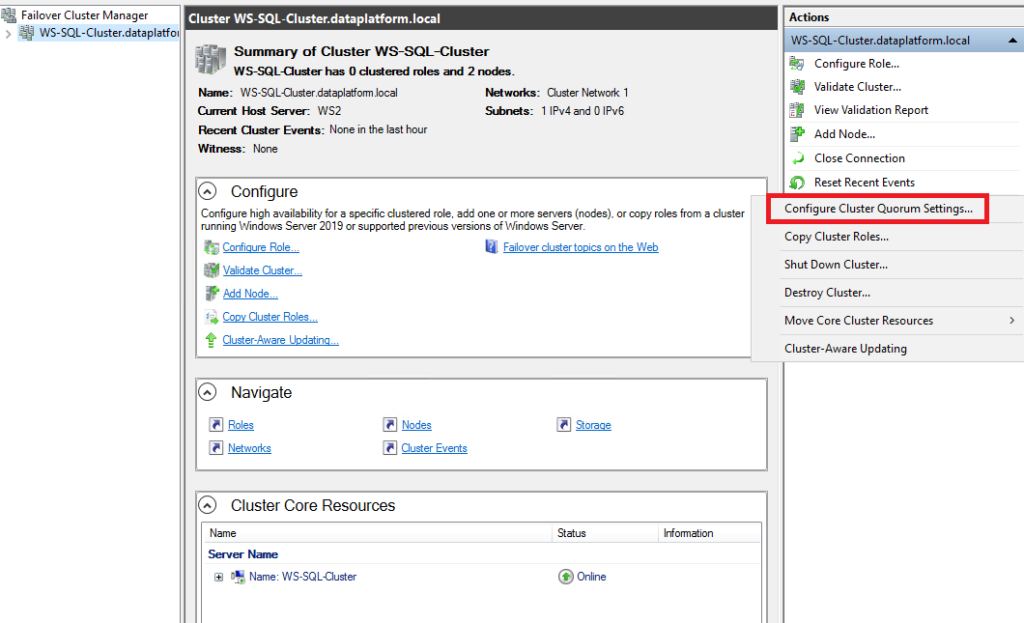
In the example we will use file share witness:
We will need a shared folder that is accessible by the Cluster and all its Nodes.
For the example I chose to create a folder on the server that hosts the Active Directory Controller.
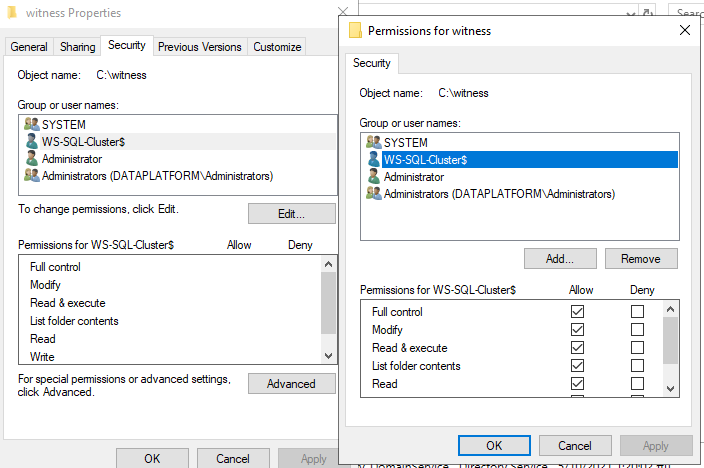
We select right click on the folder, Advanced Sharing…, Permissions, Add, Object Types (Computers), Location (the domain), we search for Nodes and add them with Allow Full Control:
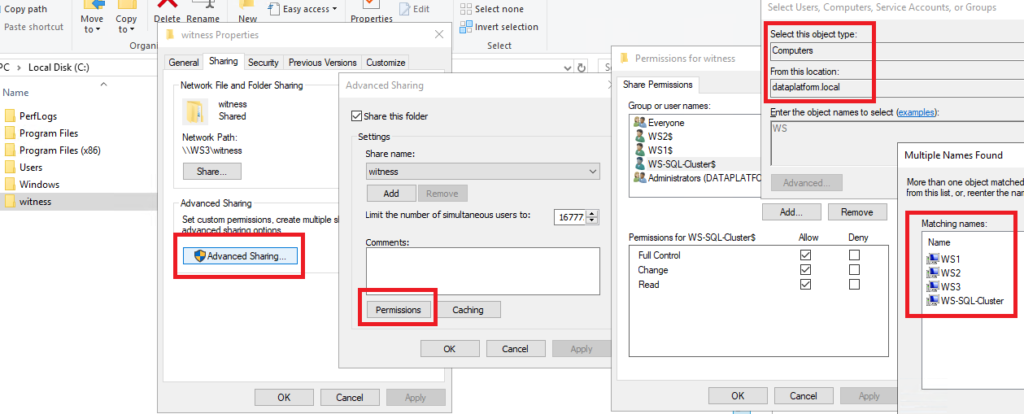
We do the same in the security tab and add the name of the Cluster:
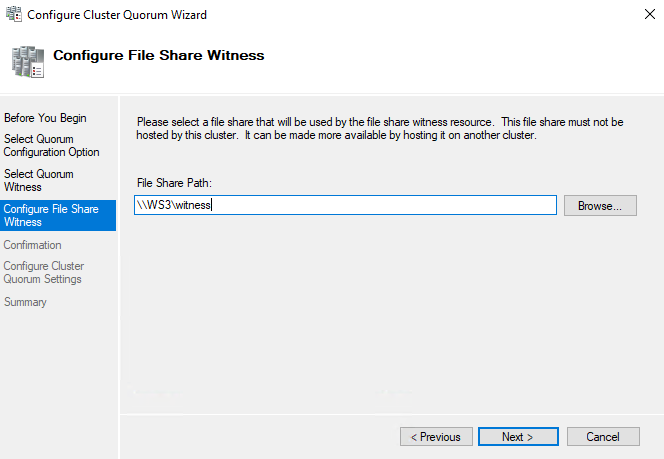
Then in the Cluster Quorum wizard we set the path with the file share and select Next until its creation is complete:
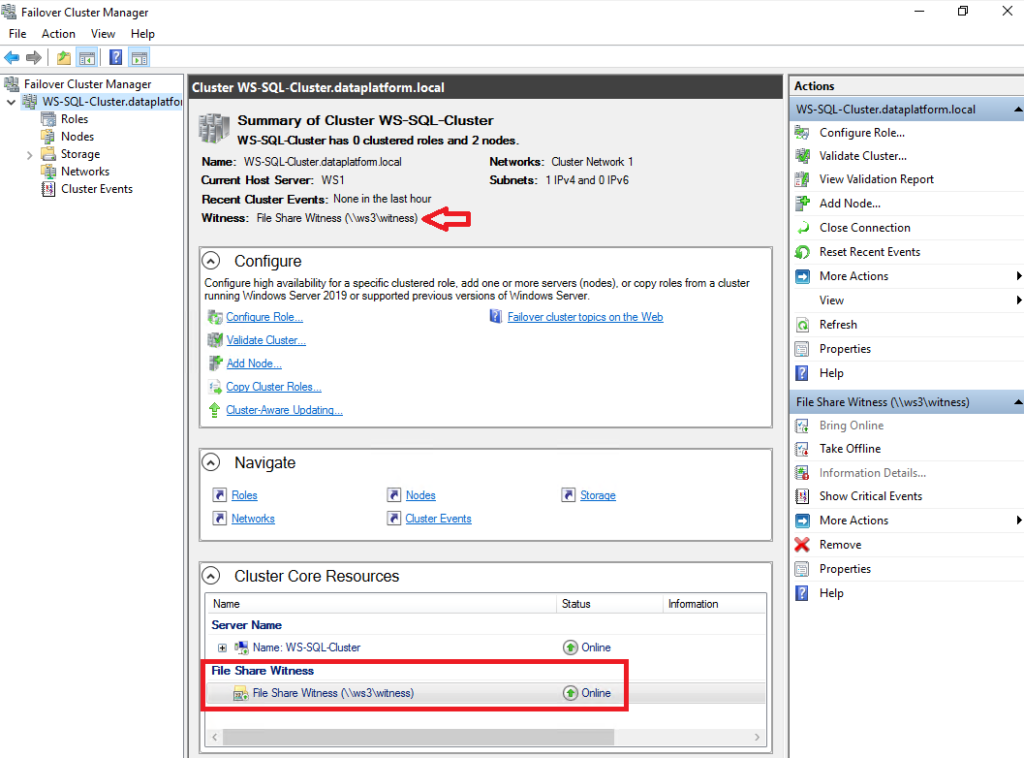
After the creation of the Witness is complete, we go back to the Failover Cluster Manager to make sure that no problem has appeared to us:
Create the Always On Availability Group
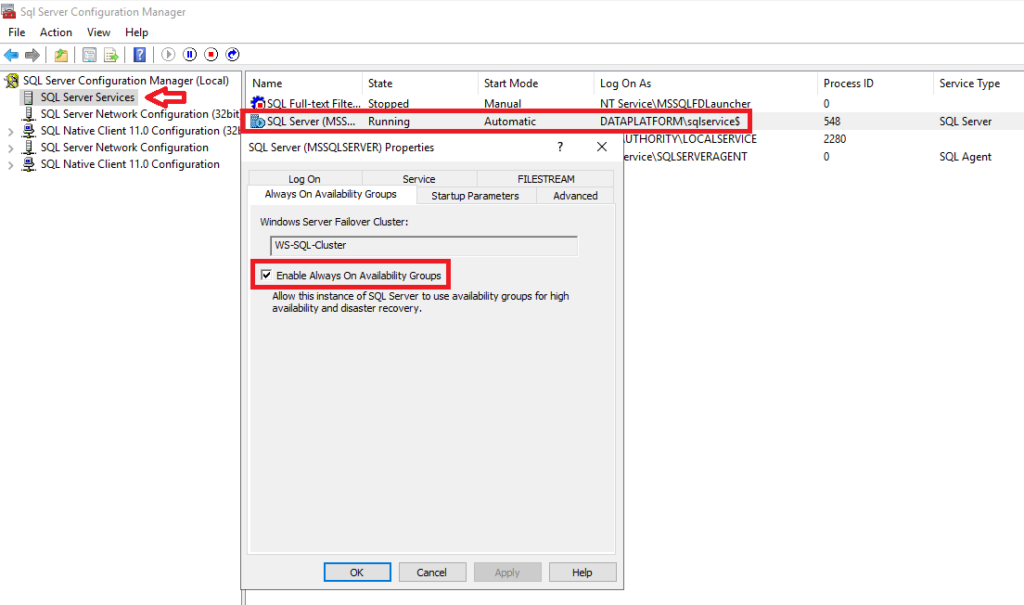
Let's go to SQL Server Configuration Manager on both Nodes and we choose SQL Server Services, right click on its service SQL Server and Properties. There you should on the tab Always On Availability Group to choose it Enable Always On Availability Groups. In case we have not yet changed the user that starts the service from the Windows default to its user or managed service Active Directory we should do it now on the tab Log On (in the example I have defined a managed service named DATAPLATFORM\sqlservice on all nodes as it must be common):
Then again in SQL Server Configuration Manager we choose SQL Server Network Configuration, Protocols for MSSQLSERVER, right click on TCP/IP and Enabled Yes:
To create the Availability Group we now connect to SQL Server Management Studio from the Primary Node (optional), right-click On Always On High Availability , Availability Groups and New Availability Group Wizard…:
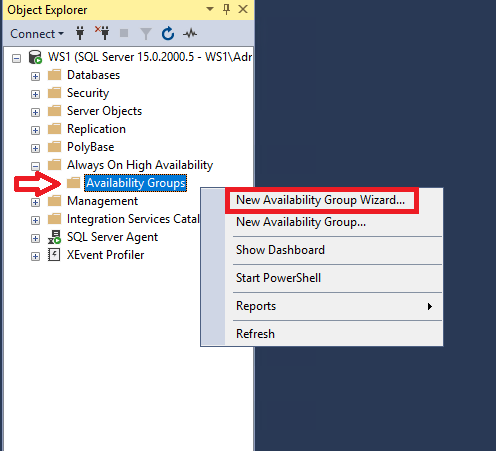
In the wizard that will appear, define the name of the Availability Group and select it Database Level Health Detection (Cluster type must be Windows Server Failover Cluster):
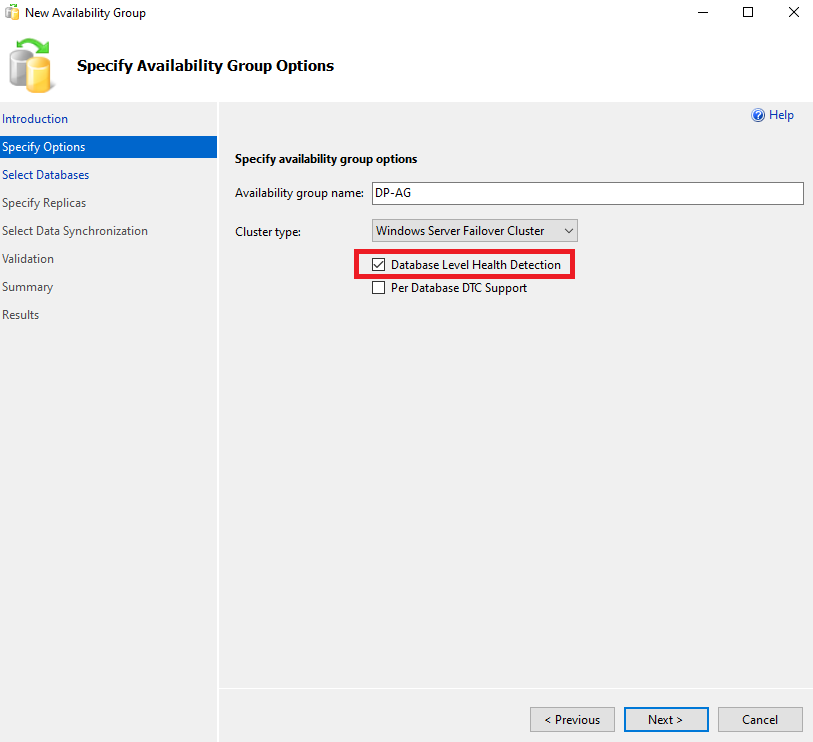
We choose the bases we want to Replicate, if we have Enterprise Edition we can choose more than one in the same group:
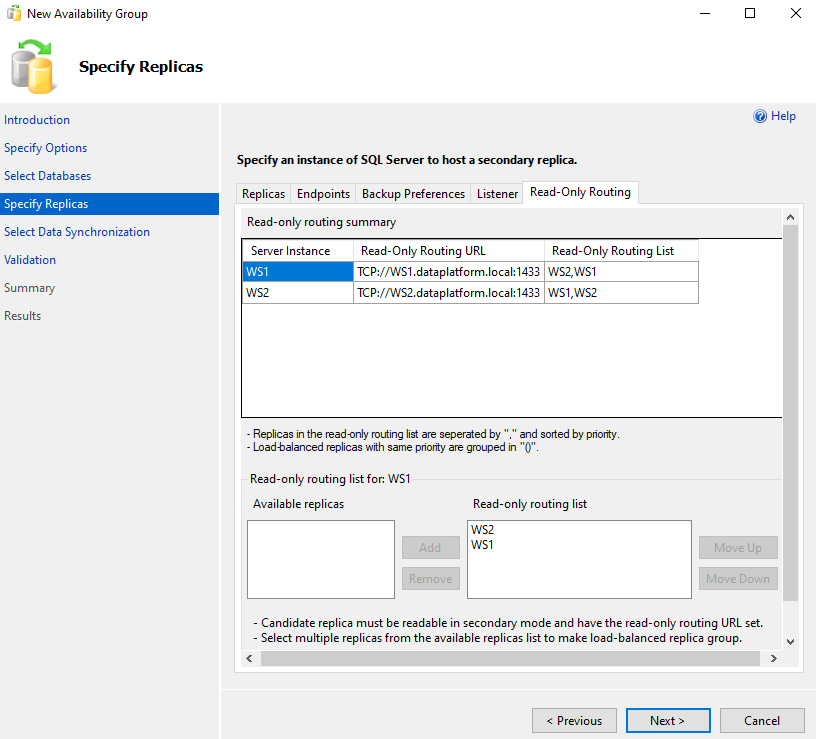
Then on the tab Replicas we also add the second Node with the selection Add Replica… .In this tab we can choose whether it will do automatic failover, whether the replication will be synchronous or asynchronous and whether the Secondary will be accessible for reading (depending on the version):
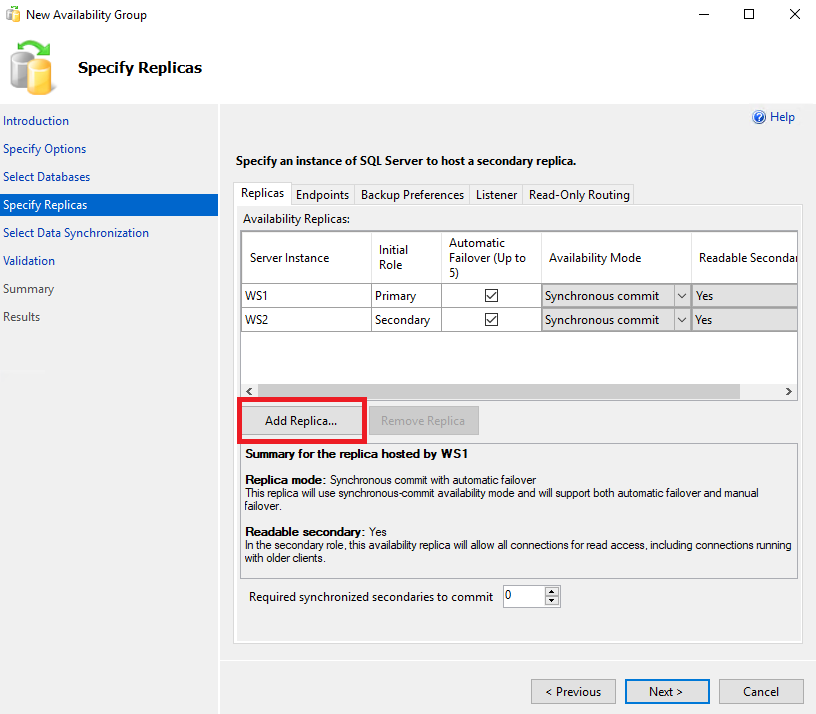
In the tab Backup Preferences (depending on the version) we can define if we want our database to take backups to Secondary instead of Primary and with what priority:
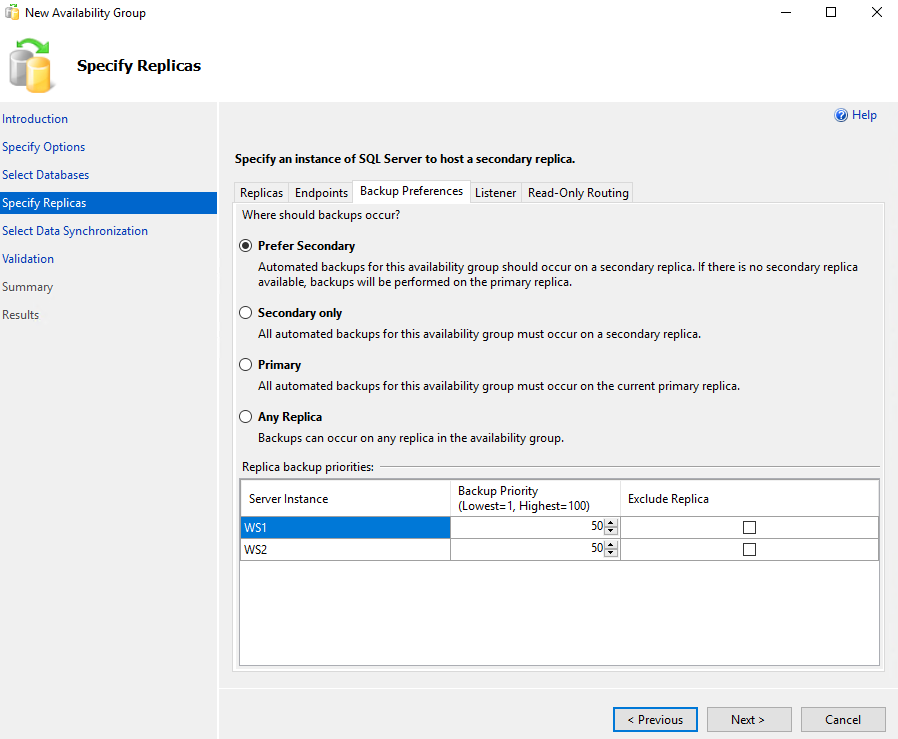
In the tab Listener we create the listener with which we can connect with a common DNS or IP to any Node according to which one is Primary (active) at the moment or if we want Read-Only access. We choose it name, door, as Network Mode Static IP and we do Add… a specific IP belonging to the subnet:
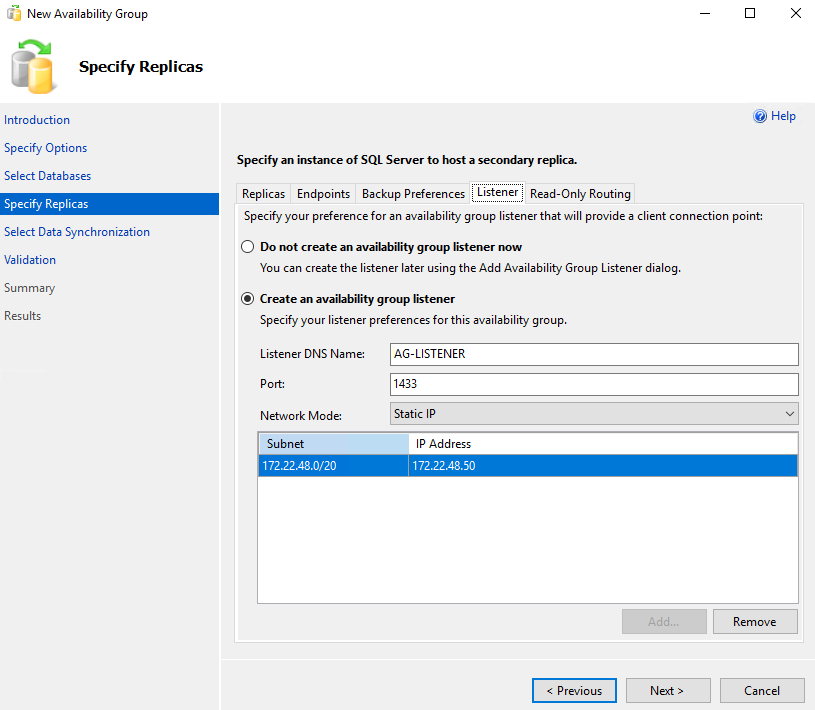
In the tab Read-Only Routing in case we want to have Read-Only access to Secondary we define them URL which will also be accessible as a Read-Only Routing List the order that will route us to Read-Only intent depending on the Instance we are connected to:
In the next tab we define the way the base will be transferred to the Secondary. We have the option for Automatic Seeding if the paths are the same without having to do anything else, the selection Full where we will define file share paths in which the backups and the selection will be placed Join only which is for the cases where we have transferred and restored the database ourselves but without having done recovery (that is, it is not yet accessible):
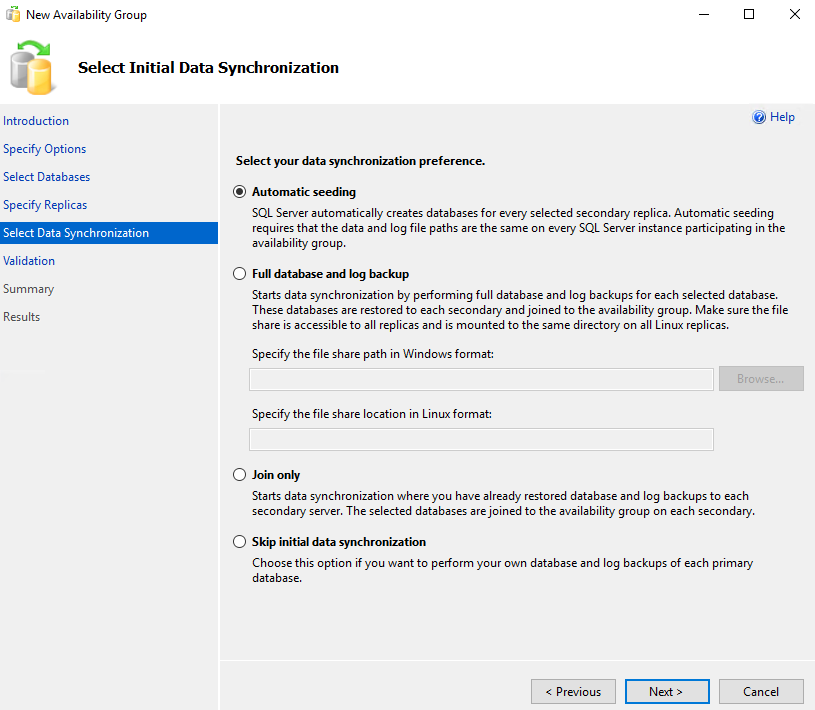
If everything goes well, we will have all Results Success:
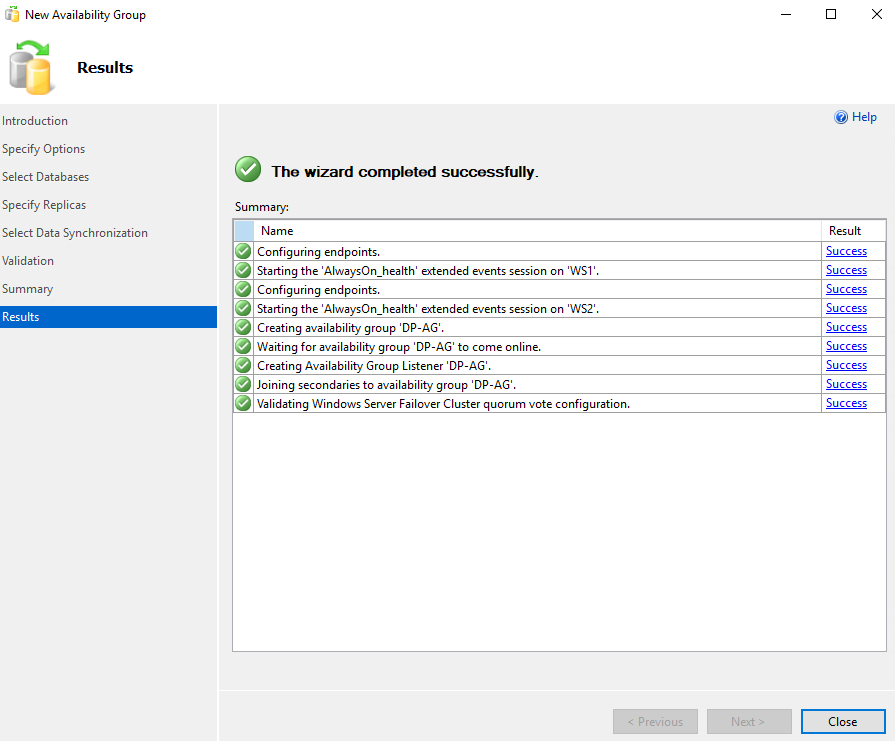
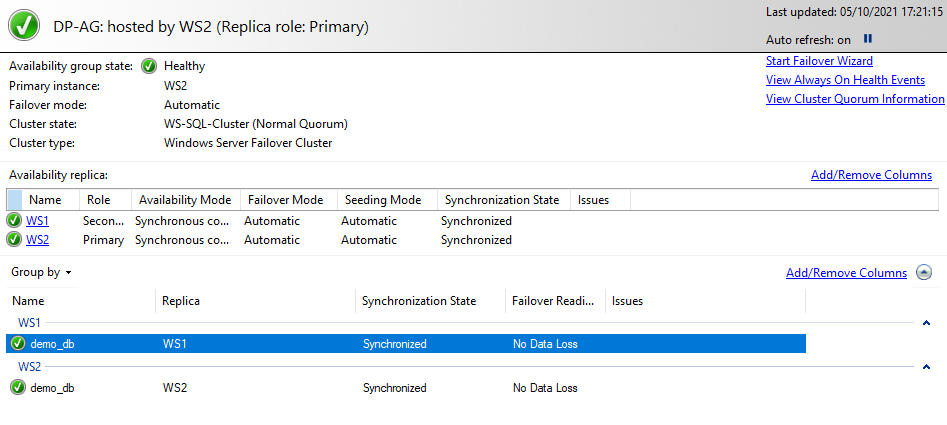
Now if we go to SQL Server Management Studio and double click on Always On High Availability, double click on Availability Groups, right click on his name Availability Group Show Dashboard we will see that the Availability Group has been created and is healthy:
We can also see this information with T-SQL with the following query:
SELECT ag.name AS [AG_Name], ar.replica_server_name AS [ReplicaServerName], ar.availability_mode_desc AS [AvailabilityMode], adc.[database_name],
hars.role_desc as [Role], drs.synchronization_state_desc as [SynchronizationState], drs.is_commit_participant as [IsCommit],
drs.synchronization_health_desc as [SyncHealth],drs.database_state_desc as [DatabaseState],
drs.last_commit_time as [Last Commit Update Time]
FROM sys.dm_hadr_database_replica_states AS drs WITH (NOLOCK)
INNER JOIN sys.availability_databases_cluster AS adc WITH (NOLOCK)
ON drs.group_id = adc.group_id
AND drs.group_database_id = adc.group_database_id
INNER JOIN sys.availability_groups AS ag WITH (NOLOCK)
ON ag.group_id = drs.group_id
INNER JOIN sys.availability_replicas AS ar WITH (NOLOCK)
ON drs.group_id = ar.group_id
AND drs.replica_id = ar.replica_id
INNER JOIN sys.dm_hadr_availability_replica_states hars
ON drs.replica_id = hars.replica_id
where 1=1
ORDER BY ag.name, ar.replica_server_name, adc.[database_name] OPTION (RECOMPILE);

What happens if the Primary Node goes down if we have selected Automatic Failover?
If for some reason the Primary node goes down, we will see on the Dashboard that the Secondary node has become Primary and the base in the former Primary is in Not Synchronizing State:
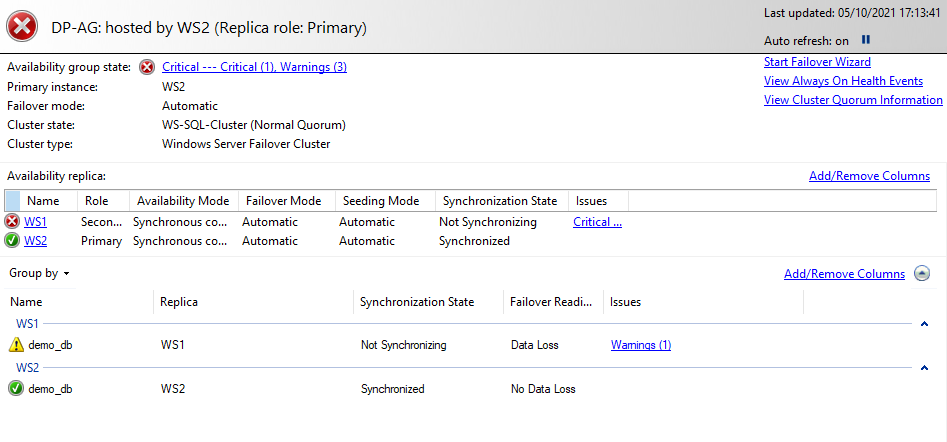

If we restore the Node after a while we will see that the Availability group is Healthy, the second Node remains as Primary but the base on the first Node has returned as Synchronized.
In case we want to turn the first Node as Primary, we select it Start Failover Wizard (we never failover through the Windows Server Failover Cluster Manager) :
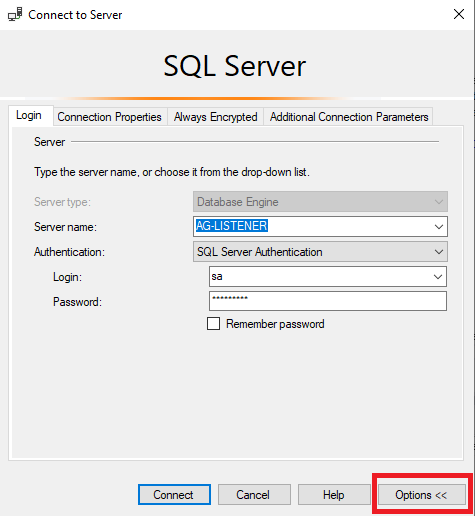
How do we connect to the Listener in a read-only Secondary
To connect to the Listener via SQL Server Management Studio, simply put its DNS or IP in the Server name. To declare that we want to connect for Read-Only we should select the option Options:
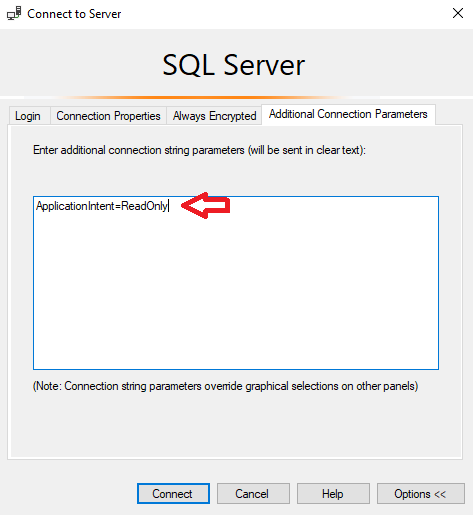
And on the tab Additional Connection Parameters to declare ApplicationIntent=ReadOnly. Thus, the select queries that we will execute in this session will be executed as a priority in Secondary:
How we create new logins
We must not forget that new logins and jobs are not transferred to Secondary automatically, so we must either have an SSIS package in Job that will create them or we must create them manually.
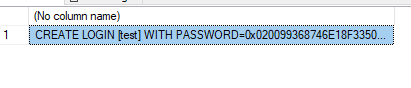
In order for a login to be correctly transferred after we have created it in Primary, we run the following query in Primary by putting in where the name of the login we created for the DDL script to create for us:
SELECT N'CREATE LOGIN ['+sp.[name]+'] WITH PASSWORD=0x'+
CONVERT(nvarchar(max), l.password_hash, 2)+N' HASHED, '+
N'SID=0x'+CONVERT(nvarchar(max), sp.[sid], 2)+N';',
N'ALTER LOGIN ['+sp.[name]+'] WITH PASSWORD=0x'+CONVERT(nvarchar(max), l.password_hash, 2)+N' HASHED UNLOCK ,CHECK_POLICY=OFF;'
FROM master.sys.server_principals AS sp
INNER JOIN master.sys.sql_logins AS l ON sp.[sid]=l.[sid]
WHERE sp.name = 'test'; -- Το αλλάζουμε ανάλογα με το όνομα του χρήστη που θέλουμε να μεταφέρουμε
After running it, select the column with the result and run the DDL in the Secondary to create the login correctly there:
Bonus Script (For Backup / Index Maintenance / Database Integrity Check SQL Server Agent Jobs)
With the following script that I have made, with just one click, it installs it MaintenanceSolution by Ola Hallengren along with ready configured jobs for Backup ,Database Integrity and Index Optimize with optimal parameters and timing.
Backup jobs are created disabled as we may have another solution for backup with a 3rd party tool. It also checks for Availability Group so that they run only if it is the Preferred Backup Replica (for backup / database integrity) and if it is Primary Replica (for Index Optimize).
All we need to do is run the following script on each SQL Server Instance: