How to write advanced SQL queries

Certifications:

In previous article we had analyzed what the SQL (Structured Query Language) and how to use it with basic examples.
In this article we will see its more advanced functions.
The code is written with the extension Transact-SQL used by SQL Server. In other RDBMS the syntax may differ such as e.g. to Oracle that uses it PL/SQL.
The structure and initial data for our examples is as follows:
create table pinakas (
id INT identity (1,1) primary key,
onoma varchar(100),
tilefono INT,
epitheto varchar(100)
)
insert into pinakas values
('Nikos','215294882′,null),
('Kwstas','210772049′,null),
('Kwstas','210772049′,null);
Correlated subquery
That Correlated subquery is the inner subquery that depends on the outer query and compares one record to another record.
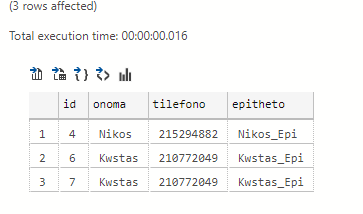
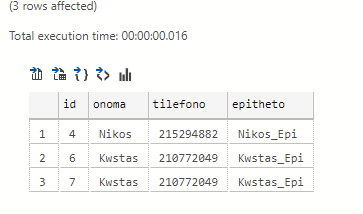
We want to update the suffix so that each record is suffixed with the name with _Epi. We will need to declare the table we are calling a second time with another alias name eg (from pinakas as p2) and we will have to set the id from the table to be equal to the same field in the alias of the same table to match line line:
update pinakas set epitheto = (select onoma+'_Epi' from pinakas as p2 where pinakas.id = p2.id) select * from pinakas
Non-correlated subquery
The Non-correlated subquery is the subquery that is executed independently of the outer query. The inner subquery is executed first and passes the results to the outer query:
select * from pinakas where id = (select 4,6,7)
After playing with the subquery let's delete the adjective column with one drop (dll statement):
alter table pinakas drop column epitheto select * from pinakas
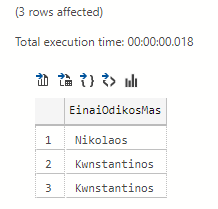
Case
Depending on the price of each registration, can we bring something else on a case-by-case basis?
Yes we can, by using it CASE:
select
CASE
WHEN onoma = 'Kwstas' THEN 'Kwnstantinos'
WHEN onoma ='Nikos' THEN 'Nikolaos'
ELSE 'Asxetos'
END AS 'EinaiOdikosMas'
from pinakas
Loops
Through SQL we can call loops like a classic while. We should declare a variable(@i) and give it a value(set). Finally it should be inside a transaction begin/end:
DECLARE @i AS INT
SET @i=5
while(@i>0)
BEGIN
PRINT('test'+@i)
SET @i=@i-1
END
Msg 245, Level 16, State 1, Line 6
Conversion failed when converting the varchar value 'test' to data type int.
Total execution time: 00:00:00.001Oops... Something went wrong, what?
Quite simply we tried to join a text with a number by converting the text to a number it doesn't happen so what do we do?
Cast
With the cast function we can convert any field into a specific data type, e.g. a number field into a text field (as is also done with the T-SQL function convert). To solve the error message that appeared to us very simply do cast the field which is a number in varchar to count as text:
DECLARE @i AS INT
SET @i=5
while(@i>0)
BEGIN
PRINT('test'+cast(@i as varchar(2)))
SET @i=@i-1
END
test5
test4
test3
test2
test1
Total execution time: 00:00:00.001Dynamic Query
We may well have code in variables and optionally concatenate them and call them as one request. How; With the Dynamic Query.
We should have defined variables that will contain each piece of code we want, then with the command EXECUTE and those variables in parentheses will be executed as if it were a complete query.
With print we see how the set of variables will be:
DECLARE @part1 as VARCHAR(100), @part2 as VARCHAR(100) set @part1='SELECT onoma' set @part2='from pinakas' print(@part1+@part2); EXECUTE (@part1+@part2)
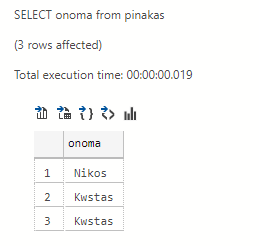
Nested Select
With the nested select we can select not from a table or view but from another select. This select can even be from the same table.
Let's look at an example:
select onoma from (select onoma,tilefono from pinakas) as nested
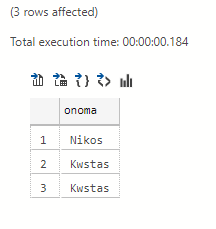
Common Table Expression or CTE
When we want a query to remain in memory with high performance as it iterates, returning subsets of data until all of the CTE it's the way.
Let's look at a simple example without much use:
We will define one CTE named dokimi_cte and we will call it with select in the next command:
with dokimi_cte as (select onoma from pinakas group by onoma) select * from dokimi_cte
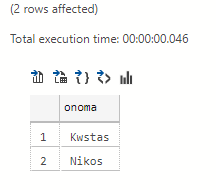
Cursors
With cursors we have the ability to scroll back and forth in the records in order to build a desired result.
In this particular example we wanted to print each name of the table by adding extra text before it.
We will make a cursor named kersoras which will be filled with the entire number of names that the table contains, as long as there are still records it will continue to do action and when it finishes it will go to the next one:
declare @names varchar(1000) declare kersoras CURSOR for select onoma from pinakas; open kersoras FETCH NEXT FROM kersoras INTO @names WHILE @@FETCH_STATUS = 0 BEGIN print 'Mr '+@names FETCH NEXT FROM kersoras INTO @names END CLOSE kersoras DEALLOCATE kersoras
Mr Nikos
Mr Kwstas
Total execution time: 00:00:00.008Select into (copy/backup one table to another)
With the select into command set we have the possibility to copy the records by creating a new table corresponding to the one we called the data:
select * into pinakas2 from pinakas select * from pinakas2
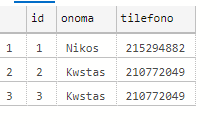
MERGE
By command MERGE we can update a table (target) with values from another table (source).
Let's say we have the table pinakas(target) and we want to update the phones with new ones. We also want to bring in new customers if there aren't any already. The information will be in the table prosorinos_pinakas(source).
Let's look at the tables in detail:
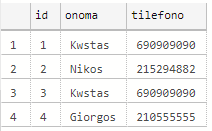
select * from pinakas
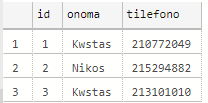
insert into prosorinos_pinakas values
('Kwstas','690909090'),
('Giorgos','210555555')
select * from prosorinos_pinakas
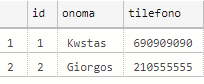
We will use a comparison field the customer's name, where it matches it will update the phone with the new one (from prosorinos_pinakas), any name it doesn't find will add the entire record to our original table (pinakas):
MERGE pinakas t
USING prosorinos_pinakas s
ON (s.onoma = t.onoma)
WHEN MATCHED
THEN UPDATE SET
t.tilefono = s.tilefono
WHEN NOT MATCHED BY TARGET
THEN INSERT (onoma,tilefono)
VALUES (s.onoma,s.tilefono);
Now if we look at the table again we will have another phone in 'Kwstas' and we will have the new customer named 'Giorgos' who did not exist:
select * from pinakas