

How can we increase performance on Oracle GoldenGate Replicat target with parallelism?

Certifications:

If we choose to do it Initial Load before synchronization via Replicat of GoldenGate or simply Replicat has a large amount of data to synchronize, one Replicat thread is not enough.
In this article we will see two ways to run the Replicat process in parallel. One way is through Classic Replicat with RANGE FILTER which has very good performance at Initial LoadThe other way is through Coordinated Replicat which is recommended for transaction synchronization because it protects against conflicts, blocks and deadlocks as the head Coordinator process coordinates the execution of DDL (ALTER, CREATE) and DML (UPDATE, INSERT, DELETE) actions in the correct order
Classic Replicat with RANGE FILTER
In this mode we can do MAP and putting RANGE FILTER in the tables that are in the parameter file of each Replicat, we can divide them into multiple partitions. This way we can create multiple different Replicat processes, each of which is responsible for applying the specific partition of the table.
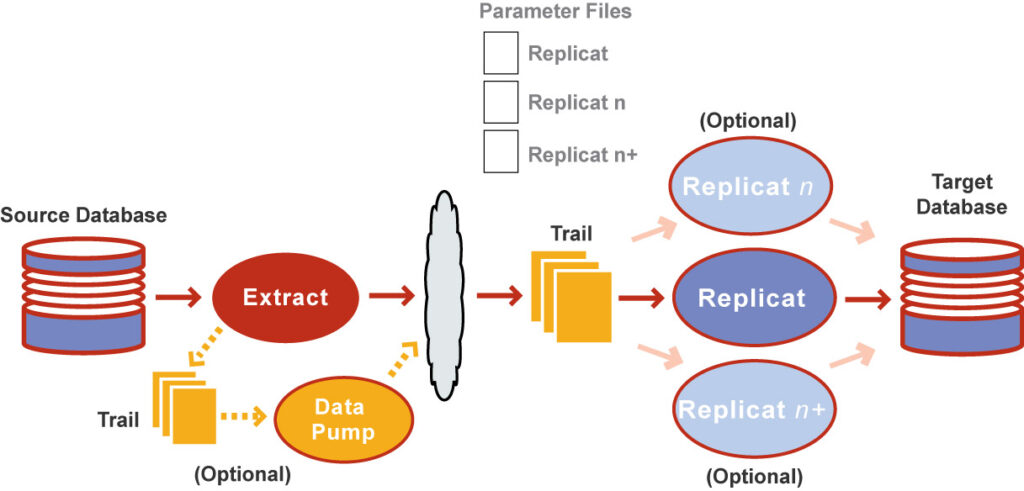
This method has excellent performance for use in Initial Load as it consists of massive INSERTS. However, we must be careful because this method cannot be used in the second phase of synchronization where we will pass transactions as the fact that DDL (ALTER, CREATE) and DML (UPDATE,INSERT,DELETE) actions are performed does not guarantee that they will be passed in the correct order. For this reason, if we try to pass transactions with this method we will have conflicts, blocks, deadlocks and errors.
Coordinated Replicat
In this function, by defining during creation that it is a coordinated replica and making MAP putting THREADRANGE in the tables found in the Replicat parameter file, you create a single process called Replicat Coordinator, this in turn creates threads accordingly THREADRANGE which we have defined and undertakes to coordinate the order in which each thread must run so that transactions do not have conflicts, blocks, deadlocks and errors.
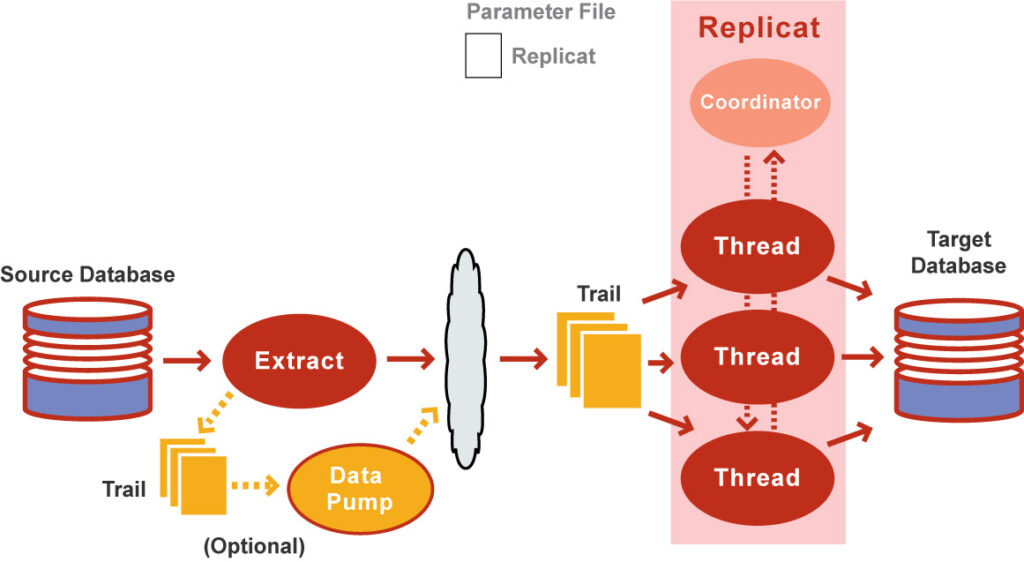
The differences between Replicat modes
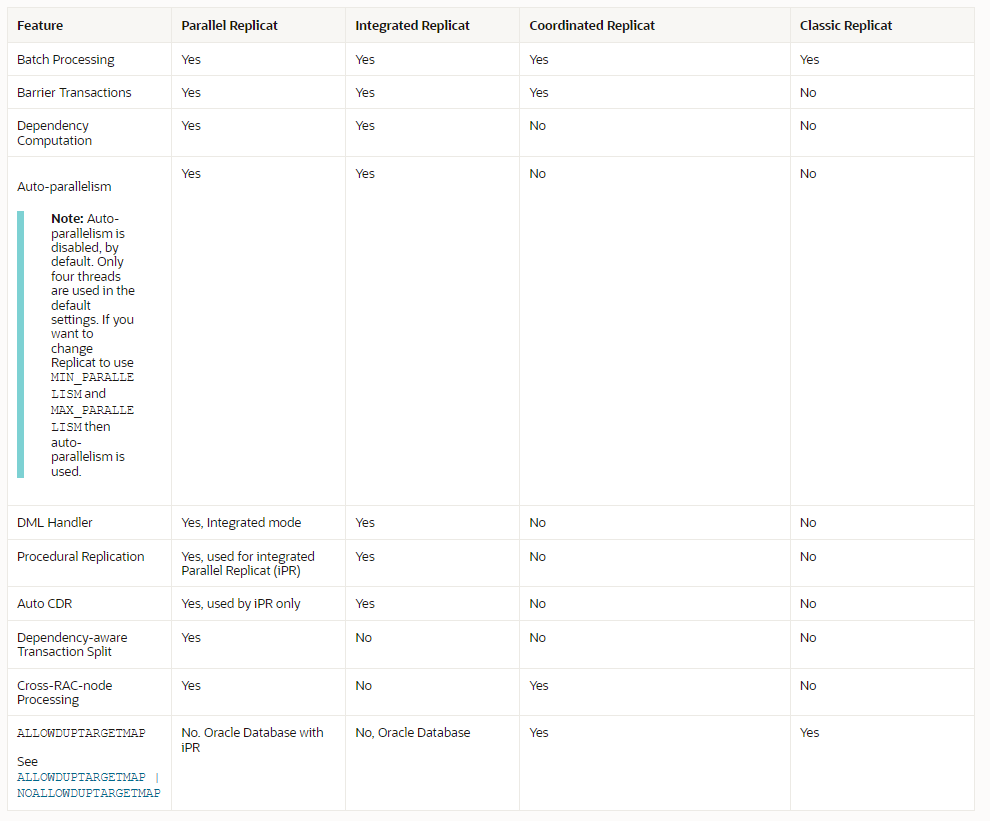
The prerequisites
For this article we assume that we already have a complete GoldenGate installation.
How to install and configure can be read in the article here.
Then for our example we will assume that we have made the following settings in the target for Extracts.
We have created and started the extract for transaction synchronization:
edit param MIS_EXT
EXTRACT MIS_EXT
USERIDALIAS GGADMIN
RMTHOST sqlserverdb.mshome.net, MGRPORT 7809
RMTFILE ./dirdat/mi, PURGE
TABLE STRATOS.CUSTOMERS;add extract mis_ext, integrated tranlog, exttrail ./dirdat/mi, BEGIN NOW
start mis_ext
We have created and started the extract for the Initial Load:
edit param INI_EXT
EXTRACT INI_EXT
USERIDALIAS GGADMIN
RMTHOST sqlserverdb.mshome.net, MGRPORT 7809
RMTFILE ./dirdat/fe, PURGE
TABLE STRATOS.CUSTOMERS;add extract ini_ext, sourceistable
Installing Classic Replicat with RANGE FILTER for Initial Load
For its installation, the only difference from a Replicat is the addition of RANGE FILTER after the MAP with a definition depending on how many Replicat Processes we want to create. For our example we will have two processes:
edit param IN1_REP
REPLICAT in1_rep
TARGETDB sqlserverdb, USERIDALIAS ggadmin
SOURCECHARSET PASSTHRU
BATCHSQL
REPERROR(60,TRANSABORT, MAXRETRIES 10, DELAYSECS 60)
DISCARDFILE ./dirrpt/sql_discard.txt, APPEND, MEGABYTES 50
FUNCTIONSTACKSIZE 500
MAP STRATOS.CUSTOMERS, TARGET DBO.CUSTOMERS FILTER (@RANGE(1,2));
edit param IN2_REP
REPLICAT in2_rep
TARGETDB sqlserverdb, USERIDALIAS ggadmin
SOURCECHARSET PASSTHRU
BATCHSQL
REPERROR(60,TRANSABORT, MAXRETRIES 10, DELAYSECS 60)
DISCARDFILE ./dirrpt/sql_discard.txt, APPEND, MEGABYTES 50
FUNCTIONSTACKSIZE 500
MAP STRATOS.CUSTOMERS, TARGET DBO.CUSTOMERS FILTER (@RANGE(2,2));Beyond the RANGE FILTER we have added the BATCHSQL, the TRANSABORT for re-executing transactions from timeouts/deadlocks and we have increased the FUNCTIONSTACKSIZE so that insert statements can be run en masse in batches, increasing performance.
Then we add these two replicat processes:
add replicat in1_rep, exttrail ./dirdat/fe add replicat in2_rep, exttrail ./dirdat/fe
And let's get started:
start in*
Installing Coordinated Replicat for transaction synchronization
To install it, we will only create a Replicat to which we will add the THREADRANGE that we want after MAP with a definition depending on how many threads we want to use. For our example we will set 8 threads:
edit param mirep
REPLICAT mirep
TARGETDB sqlserverdb, USERIDALIAS ggadmin
SOURCECHARSET PASSTHRU
REPERROR(60,TRANSABORT, MAXRETRIES 10, DELAYSECS 60)
DISCARDFILE ./dirrpt/sql_discard.txt, APPEND, MEGABYTES 50
DISCARDROLLOVER AT 03:00 ON TUESDAY
REPORTROLLOVER AT 03:00 ON TUESDAY
FUNCTIONSTACKSIZE 500
HANDLECOLLISIONS
APPLY_PARALLELISM 8MAP STRATOS.CUSTOMERS, TARGET DBO.CUSTOMERS THREADRANGE(1-8);
The parameter HANDLE COLLISIONS we define it so that we don't have a problem with the initial synchronization with conflicts from the Initial Load, we can remove it later. If we want it to run only in one thread on the specific table instead of THREADRANGE we put THREAD(1)Optionally if we want it to run with 8 threads by default on any table we define APPLY_PARALLELISM 8.
Then we add and start the Coordinated Replicat process:
add replicat mirep, coordinated, exttrail ./dirdat/mi start mirep
In case we want to start from a specific trail file and rba:
add replicat mirep, coordinated, exttrail ./dirdat/fe, extseqno=55, extrba=1292840
When we start it we set the parameter FILTERDUMPTRANSACTIONS so that transactions that have already passed can be checked:
start mirep FILTERDUPTRANSACTIONS
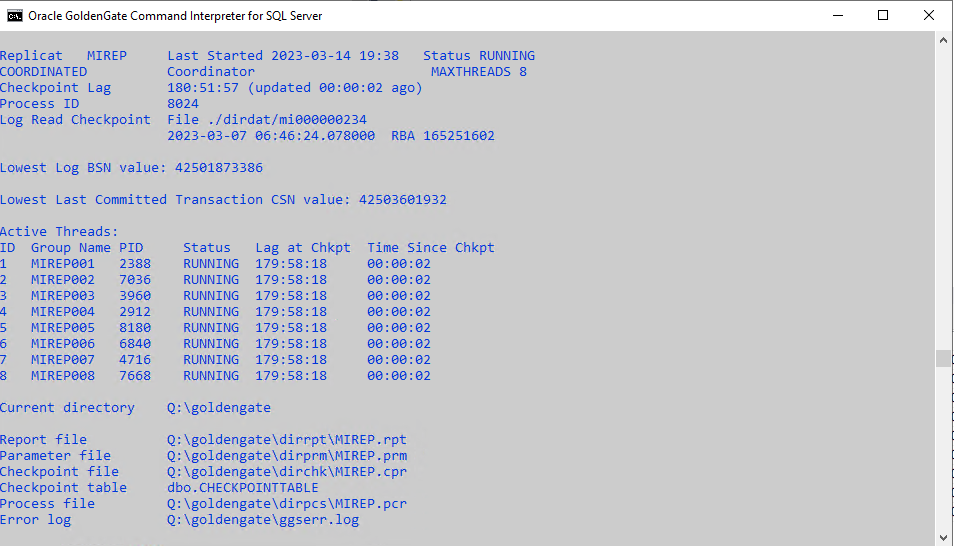
Once it starts, we will see that Coordinated Replicat has created eight threads underneath it:
info mirep, detail
In case of abnormal stop of Coordinated Replicat
In the event that Coordinated Replicat aborts or closes unexpectedly, we must synchronize it with the command before starting it again. synchronize so that all threads are at the same point in time:
synchronize replicat mirep
When the synchronization is complete we will see that it has stopped, then we can start it again:
start mirep